
Tóm tắt: Chào bạn đọc, bài viết này sẽ giúp bạn hiểu rõ về “Attention”, một khái niệm quan trọng trong kiến trúc Transformer, nền tảng cho những mô hình ngôn ngữ lớn như ChatGPT, Claude, Bard. Chúng ta sẽ khám phá “Attention” là gì, cách nó hoạt động, lý do nó được ứng dụng rộng rãi và cả những điểm mạnh, điểm yếu của nó.
Mở đầu:
Bạn đã từng nghe về ChatGPT, Claude, Bard – những siêu AI ngôn ngữ đang khuynh đảo thế giới, phải không?
Bí mật đằng sau sức mạnh của những AI này chính là kiến trúc Deep Learning “Transformer”. Và ẩn sau sức mạnh của Transformer là một cơ chế “thầm lặng” nhưng vô cùng thông minh – “Attention”.
Bài viết này sẽ đưa bạn khám phá bí mật của “Attention” – người hùng thầm lặng đã góp phần tạo nên cuộc cách mạng AI.
Table of Contents
1. Mạng neuron: Nền tảng của Deep Learning
Để hiểu “Attention”, chúng ta cần bắt đầu với một khái niệm cơ bản: mạng neuron.
Mạng neuron là một mô hình học máy (Machine Learning) được lấy cảm hứng từ cấu trúc não người.
- Đầu vào: Một hình ảnh, một câu, hay bất kỳ dữ liệu nào sẽ được máy mã hóa thành một bộ các con số (vector A).
- Nút (Neuron): Mỗi con số trong vector A được coi là một nút, hay còn gọi là neuron.
- Liên kết: Các neuron được kết nối với nhau bằng các liên kết, mỗi liên kết có một giá trị thể hiện mức độ “nặng” của nó (weight: W).
- Tính toán: Các neuron kết nối với nhau bằng cách nhân đầu vào với trọng số (input * weight).
- Kết quả: Sau khi tính tổng các kết quả của các neuron, kết quả Z được đưa qua một hàm kích hoạt (activation function) để cho ra kết quả cuối cùng của mô hình.
Bạn có thể tìm hiểu thêm về mạng neuron tại But what is a neural network.
2. Deep Learning: Nâng tầm khả năng của máy tính
Deep Learning là một nhánh của Machine Learning, sử dụng mạng neuron để học các quy luật phức tạp từ dữ liệu đầu vào. Deep Learning đã tạo nên những bước tiến vượt bậc trong nhiều lĩnh vực như nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên, dịch thuật và nhiều hơn nữa.
3. Dữ liệu dạng chuỗi: Khi thứ tự quan trọng
Dữ liệu dạng chuỗi là loại dữ liệu mà thứ tự của các thành phần ảnh hưởng đến giá trị của dữ liệu. Ví dụ, trong một câu, thứ tự các từ ảnh hưởng đến nghĩa của câu đó. Các dữ liệu như văn bản, âm thanh, sóng… đều là dữ liệu dạng chuỗi.
4. Transformer: Cách mạng hóa xử lý ngôn ngữ tự nhiên
Để xử lý dữ liệu dạng chuỗi một cách hiệu quả, các nhà khoa học đã phát triển kiến trúc Deep Learning “Transformer”. Transformer được thiết kế để xử lý dữ liệu có tính ngữ cảnh, giúp máy hiểu được ý nghĩa sâu xa của dữ liệu.
5. “Attention”: Bí mật đằng sau sự thông minh của AI
“Attention” là một cơ chế “thầm lặng” nhưng vô cùng thông minh, đóng vai trò quan trọng trong kiến trúc Transformer. “Attention” giúp Transformer tập trung vào những phần tử quan trọng trong dữ liệu, từ đó nâng cao hiệu quả xử lý và hiểu ngữ cảnh.
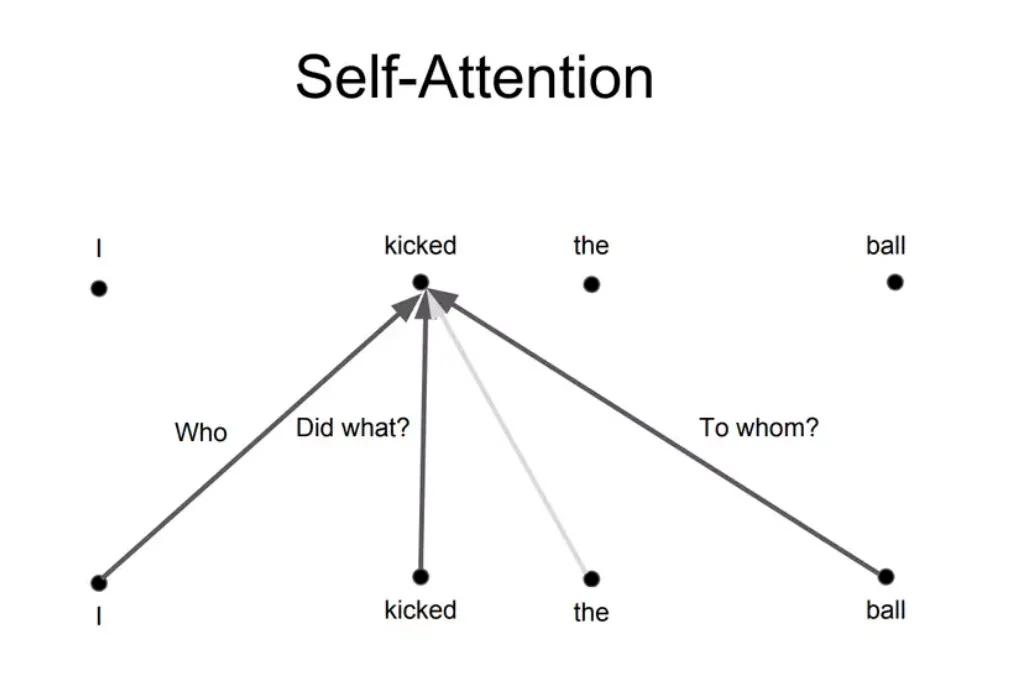
6. Cách thức hoạt động của “Attention”
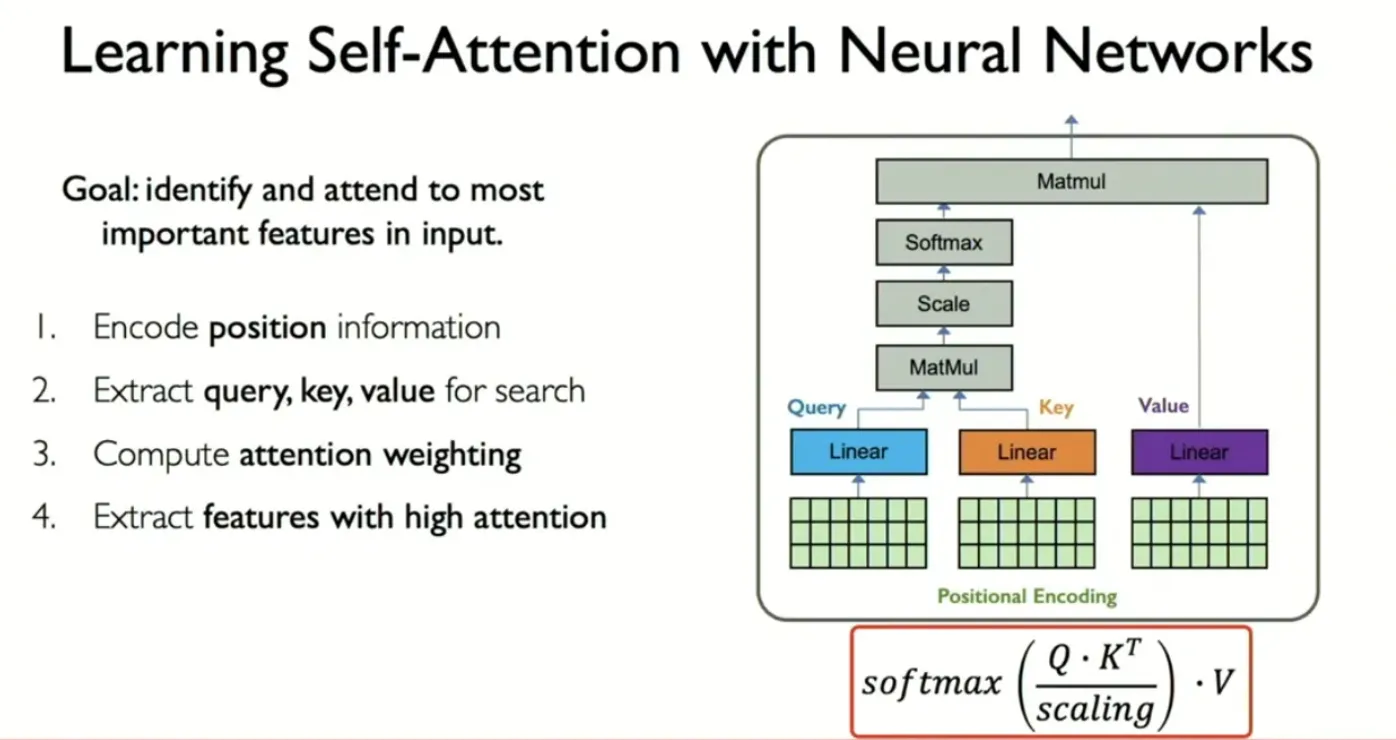
“Attention” hoạt động theo 4 bước chính:
6.1 Mã hóa thông tin về vị trí của các phần tử (Encode Positional Infos):
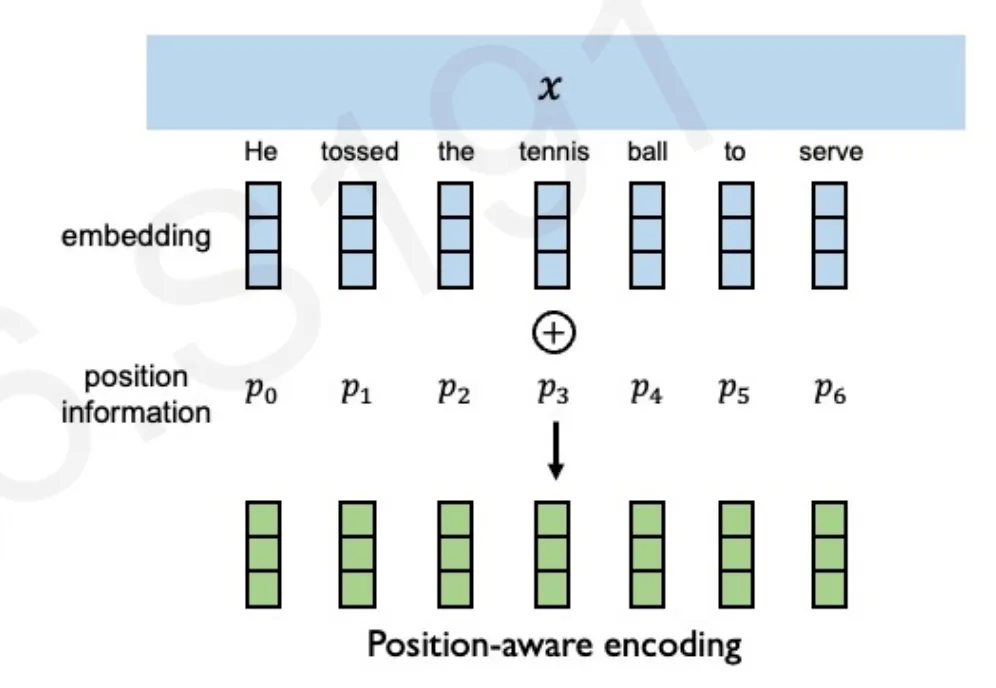
Toàn bộ dữ liệu được đưa vào hệ thống cùng một lúc, và vị trí của mỗi Token (mảnh dữ liệu nhỏ) được mã hóa thành các bộ số mà máy có thể hiểu (Positional Encoding).
6.2 Tách giá trị Key, Value, Query (Key, Query, Value extraction):
Giá trị Positional Encoding được nhân với 3 bộ Weight (Wq, Wk, Wv). Mỗi bộ Weight tương tự như một “bộ nhớ tạm thời” với chức năng khác nhau:
- Wq: Cho ra giá trị Q: Query (phần hỏi) – màu xanh dương.
- Wk: Cho ra giá trị K: Key (phần hồi đáp một cách tóm tắt) – màu cam.
- Wv: Cho ra giá trị V: Value (Câu trả lời một cách cụ thể) – màu tím nhạt.
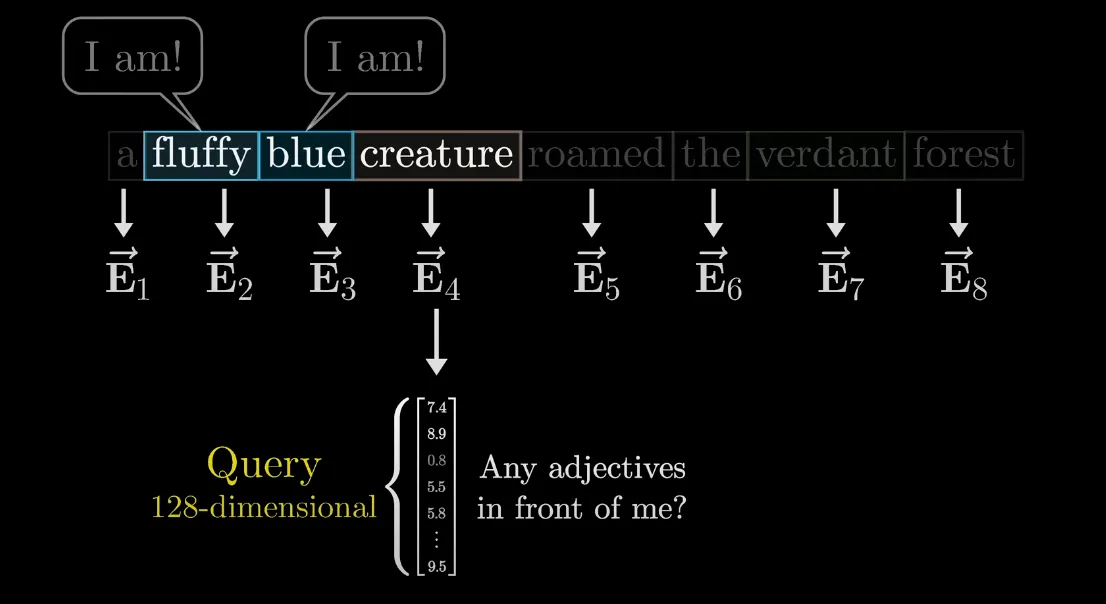
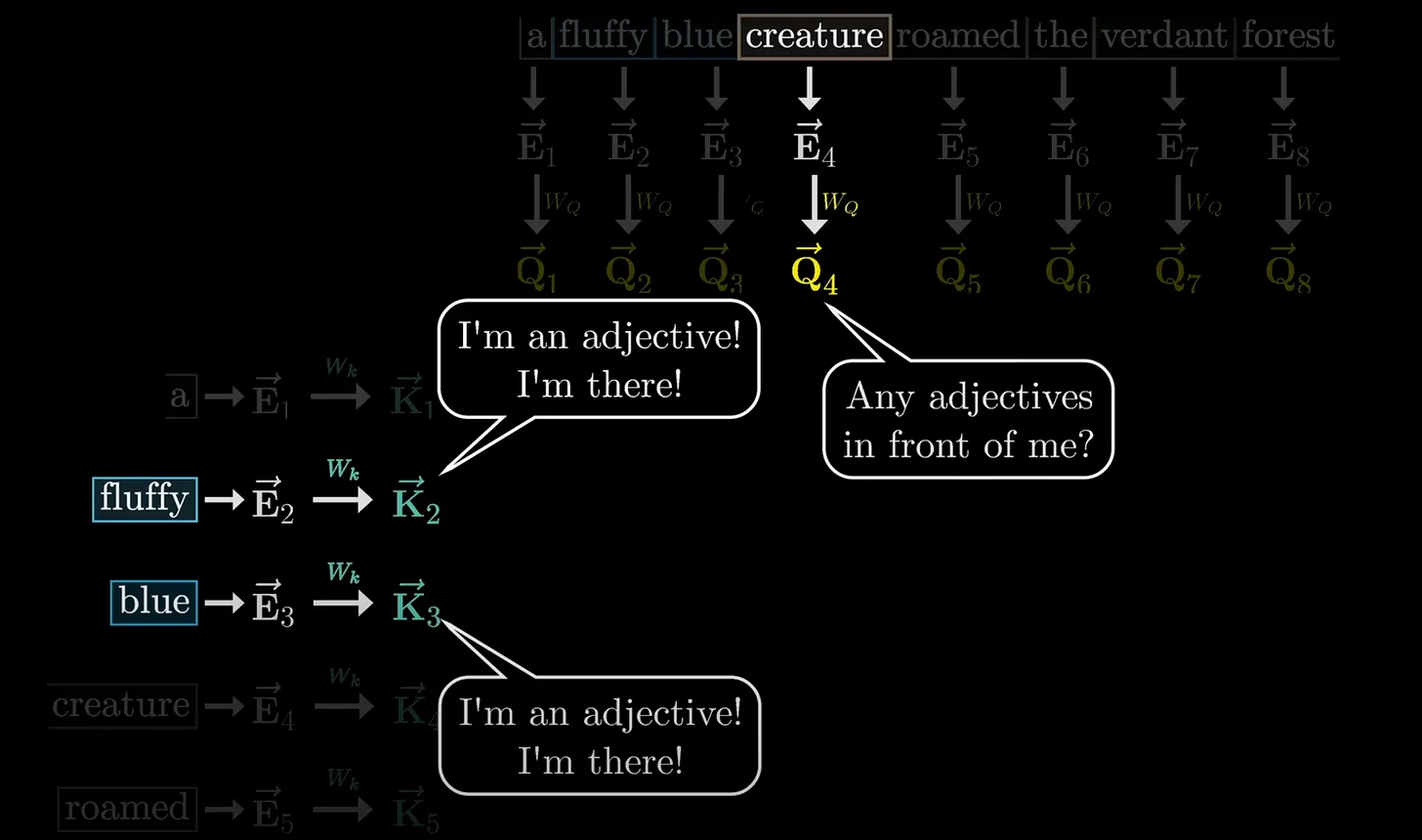
6.3 Tính Attention Weight (Compute Attention Weight):

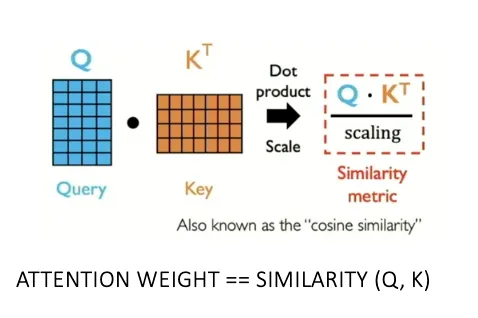
Để xác định mức độ liên quan giữa các Key và Query, một phép nhân vô hướng (Dot-product) được thực hiện giữa 2 vector, hay còn gọi là độ tương đồng cosine (Cosine Similarity).
Giá trị của phép nhân vô hướng càng lớn, chứng tỏ Key có liên quan đến Query.
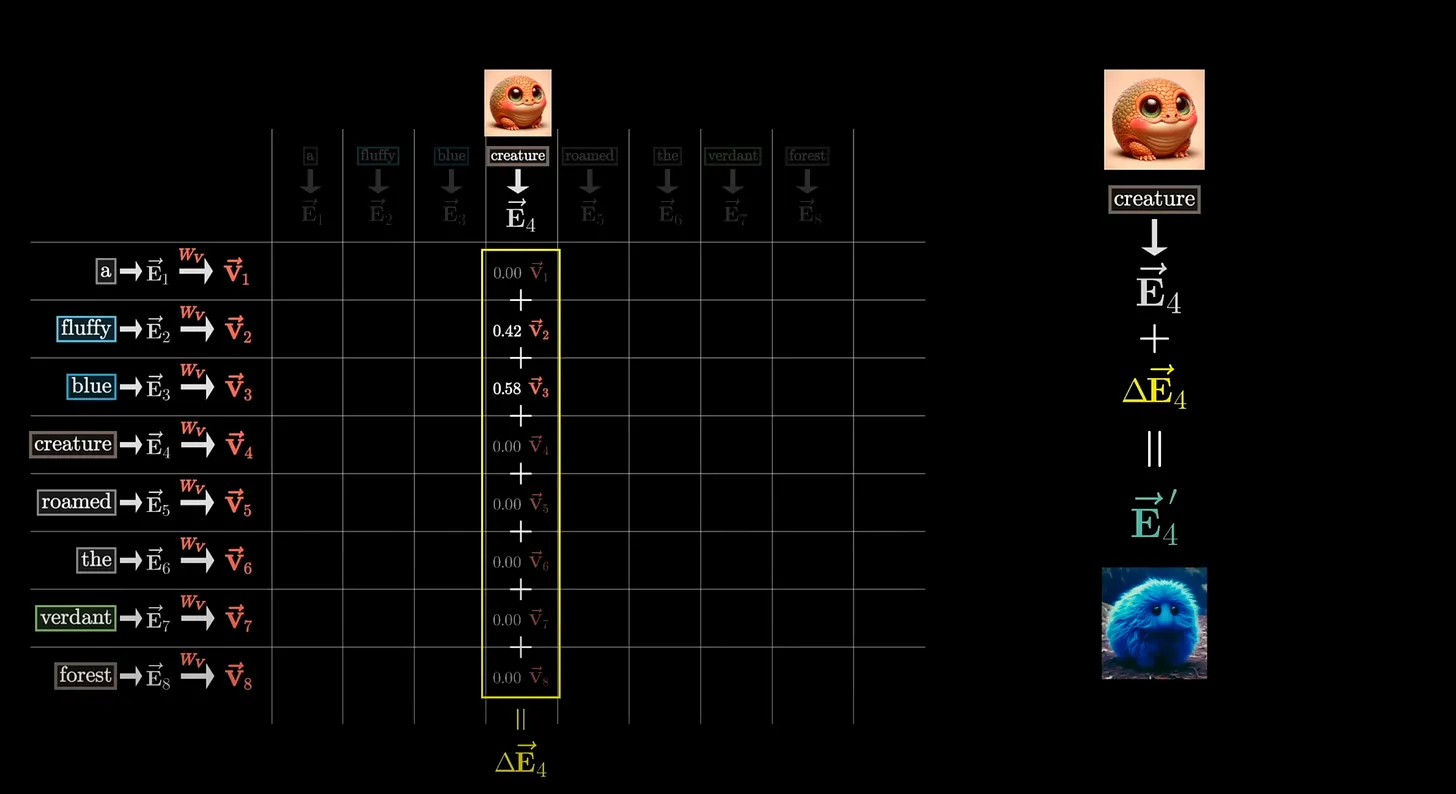
6.4 Tách các thông tin liên quan (Extract Relevant Features):

Bước này dùng để lấy ra các thông tin ngữ nghĩa để bổ sung cho các Token thông qua Attention Weight và Value.
- Soft-max: Attention Weight được đưa qua hàm Soft-max để đảm bảo giá trị của nó nằm trong khoảng [0,1].
- Value: Giá trị Value được giữ nguyên để đảm bảo thông tin cụ thể về ngữ cảnh không bị áp đảo bởi hàm Soft-max.

7. Tại sao “Attention” lại quan trọng?
“Attention” ra đời để giải quyết các vấn đề trong dịch thuật ngôn ngữ (Machine Translation) – nơi dữ liệu đầu vào là các từ, câu (Sequential Data).
Trước khi có “Attention”, người ta thường sử dụng mạng neuron tuần hoàn (Recurrent Network – RNN) để dịch thuật. Tuy nhiên, RNN có những hạn chế:
- Khả năng nhớ ngắn: RNN chỉ có thể nhớ thông tin trong một khoảng thời gian ngắn, dễ bị quên mất ngữ cảnh của toàn bộ dữ liệu, gây khó khăn khi dịch các văn bản dài.
- Tốc độ chậm: RNN xử lý dữ liệu chậm hơn, bởi nó tập trung vào từng phần tử một cách riêng lẻ.
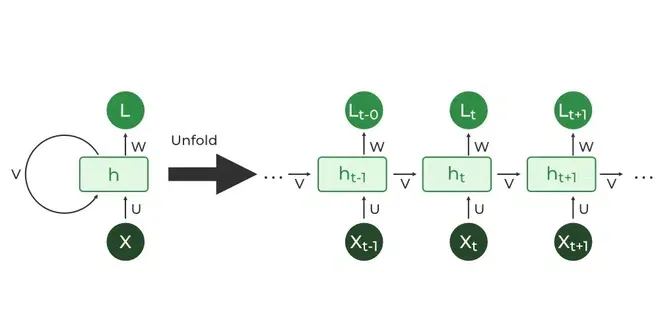
“Attention” giải quyết những hạn chế này của RNN:
- Xử lý ngữ cảnh hiệu quả: “Attention” giúp các mô hình Deep Learning nắm bắt ngữ cảnh của dữ liệu hiệu quả hơn, từ đó đưa ra kết quả chính xác hơn.
- Tốc độ xử lý nhanh hơn: “Attention” giúp quá trình xử lý dữ liệu nhanh hơn so với các mô hình truyền thống như RNN.
- Dễ dàng tối ưu hóa: “Attention” giúp việc tối ưu hóa mô hình Deep Learning trở nên dễ dàng hơn.
8. Ưu điểm và Nhược điểm của “Attention”:
| Ưu điểm | Nhược điểm |
| Xử lý thông tin ngữ cảnh hiệu quả | Yêu cầu tài nguyên tính toán lớn |
| Tốc độ xử lý nhanh hơn | Khó giải thích kết quả |
| Dễ dàng tối ưu hóa |
9. Nhận xét:
“Attention” là một khái niệm quan trọng trong Deep Learning, góp phần tạo nên những đột phá trong lĩnh vực AI. Hiểu rõ “Attention” giúp chúng ta hiểu rõ hơn về những mô hình ngôn ngữ lớn như ChatGPT và sức mạnh của trí tuệ nhân tạo.
“Attention” đóng vai trò quan trọng trong việc giúp các mô hình Deep Learning hiểu được ngữ cảnh của dữ liệu và đưa ra kết quả chính xác hơn. Tuy nhiên, “Attention” cũng có những hạn chế như yêu cầu tài nguyên tính toán lớn và khó giải thích kết quả. Dù sao, đây là một công nghệ đầy tiềm năng và sẽ tiếp tục phát triển trong tương lai.
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist