")
Table of Contents
Giới thiệu
Vào tháng 12 năm 2023, Hội đồng Châu Âu và Nghị viện Châu Âu đã đạt được thỏa thuận tạm thời về một bộ quy tắc hài hòa mới về trí tuệ nhân tạo—Đạo luật AI. Đạo luật AI là quy định nhằm đảm bảo an toàn và tuân thủ các quyền cơ bản và giá trị của EU, đồng thời duy trì mục tiêu khuyến khích đổi mới và đầu tư vào AI.
Các mục tiêu của Đạo luật AI có khả năng xung đột nhau. Quả thực, rõ ràng là quy định làm tăng thêm chi phí và sự không chắc chắn có thể cản trở quá trình cạnh tranh, chẳng hạn như bằng cách giảm các biện pháp khuyến khích R&D. Việc theo đuổi các mục tiêu xung đột nhau không phải là hiếm và cũng không hẳn là điều xấu, miễn là cơ quan quản lý và công chúng nhận thức được sự đánh đổi liên quan.
Bất kỳ điều luật mới quan trọng nào cũng chắc chắn sẽ gây ra một cuộc tranh luận sôi nổi trong công chúng về sự cân bằng giữa các mục tiêu đó. Bài viết này nhằm mục đích cung cấp những hiểu biết sâu sắc hơn về phản ứng của công chúng đối với Đạo luật AI và quan điểm chung của nó liên quan đến AI. Để đạt được mục tiêu này, bài viết phân tích dữ liệu từ nền tảng truyền thông xã hội X (trước đây là Twitter), nền tảng này cung cấp những hiểu biết sâu sắc và bình luận công khai từ các nhà lãnh đạo doanh nghiệp, các nhà hoạch định chính sách và công chúng nói chung.
Dữ liệu từ các nền tảng truyền thông xã hội có dạng văn bản miễn phí hoặc “ngôn ngữ tự nhiên”. Theo nghĩa đó, nó khác với dữ liệu có cấu trúc, được sắp xếp trong các bảng với các trường và giá trị được đặt tên mà các nhà kinh tế sẽ đối chiếu và sau đó điều chỉnh các mô hình kinh tế lượng phù hợp. Phân tích văn bản miễn phí yêu cầu cách tiếp cận xử lý ngôn ngữ tự nhiên (NLP).
NLP cho phép phân tích định lượng văn bản. Mặc dù đã tồn tại như một lĩnh vực nghiên cứu trong nhiều thập kỷ nhưng nó đã chứng kiến sự phát triển nhanh chóng trong mười năm qua. Tập hợp các mô hình ngôn ngữ lớn (LLM) gần đây nhất — chẳng hạn như GPT4 từ OpenAI 1 hoặc LLaMA từ Meta 2 — là những ví dụ về các mô hình NLP rất hiệu quả về độ chính xác mà chúng có thể tạo ra văn bản theo lời nhắc của người dùng, thường phù hợp hoặc vượt qua chất lượng phản hồi ở cấp độ con người. Chính nhờ hiệu suất thành công này mà các mô hình như vậy hiện được gọi thay thế cho nhau là “mô hình AI”.
Ngoài việc tạo văn bản, các mô hình NLP còn rất hiệu quả để trích xuất thông tin từ văn bản — ví dụ: để hiểu các chủ đề chính của văn bản hoặc phân loại văn bản thành các danh mục khác nhau. Mặc dù nhiều cách tiếp cận NLP truyền thống sẽ phù hợp cho bài tập này, nhưng phân tích trong bài viết này sử dụng mô hình LLM để phân tích dữ liệu X. LLM hiện đại cung cấp kết quả trích xuất văn bản rất chính xác và phù hợp hơn nhiều với các bối cảnh như dữ liệu truyền thông xã hội. Sử dụng mô hình này, phân tích sẽ giải mã những gì mọi người đang nói đến và cảm nhận của họ về nó. Có lẽ thật bất ngờ, các phản ứng đối với Đạo luật AI lại trái chiều và một số chủ đề (chẳng hạn như đổi mới) lại phân cực hơn những chủ đề khác.
Phản ứng của công chúng chứng tỏ điều gì?
Đạo luật AI được đề xuất lần đầu tiên vào tháng 4 năm 2021. Kể từ đó, đã có khoảng 135.000 bài đăng về chủ đề này, 3 bài với hoạt động đạt đỉnh điểm vào tháng 6 năm 2023, khi Nghị viện Châu Âu thông qua văn bản “thỏa hiệp” và vào tháng 12 năm 2023, khi Nghị viện và Hội đồng đã đạt được thỏa thuận tạm thời về Đạo luật.
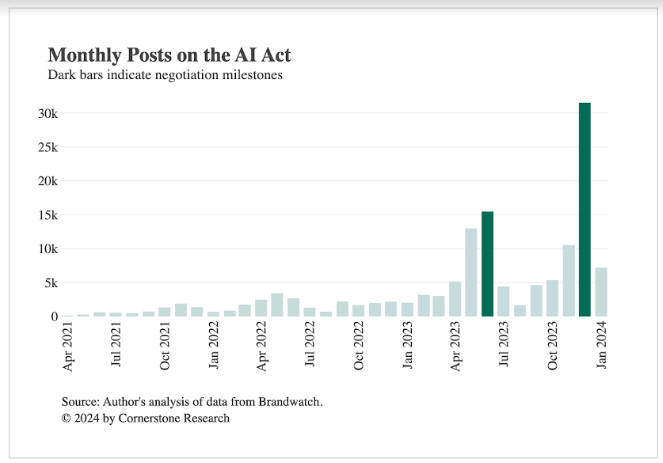
Tác giả của các bài đăng được phân tích bao gồm các nhà hoạch định chính sách, những người tham gia và quan sát viên trong ngành, thành viên của giới truyền thông, doanh nhân và thành viên của công chúng. Các bài viết bao gồm cả quan sát thực tế và ý kiến. Ví dụ: một bài đăng có thể chỉ ghi chú một cột mốc cụ thể trong quá trình áp dụng, bày tỏ mối quan ngại về một khía cạnh cụ thể của Đạo luật hoặc tôn vinh những lợi ích dự kiến của nó.
Việc đánh giá thủ công đơn giản của con người đối với các bài đăng có thể cung cấp những hiểu biết có giá trị—đặc biệt khi được mở rộng cho một mẫu lớn. Tuy nhiên, cách tiếp cận này không dễ dàng nhân rộng và không có quy mô hiệu quả. Yêu cầu con người gắn nhãn cho mỗi bài đăng và xác định một số yếu tố chính vừa dễ xảy ra lỗi vừa tốn thời gian. Tự động hóa công việc này bằng LLM có thể giải nén nội dung trên quy mô lớn bằng phương pháp được xác định chính xác. Điều này rất quan trọng, chẳng hạn như khi gửi loại phân tích này làm bằng chứng trong tố tụng pháp lý.
Việc sử dụng LLM một cách an toàn để sử dụng hiệu quả trên quy mô lớn là điều không hề đơn giản. Mặc dù quyền truy cập vào các chatbot như ChatGPT cung cấp giao diện chung, dễ tiếp cận cho người dùng công cộng, nhưng việc chạy các mô hình đó một cách an toàn ở quy mô lớn để tiến hành phân tích dữ liệu mạnh mẽ đòi hỏi phải có kiến thức khoa học dữ liệu và cơ sở hạ tầng chuyên biệt đáng kể.
Việc lựa chọn và triển khai LLM thích hợp đòi hỏi khả năng phán đoán và kiến thức tốt về bối cảnh mô hình. Một số LLM khác nhau được cung cấp bởi các tập đoàn và nhà nghiên cứu và khác nhau về chất lượng đối với các trường hợp sử dụng cụ thể, hiệu suất hoạt động, bảo mật và chi phí tài chính.
Phân tích trong bài viết này sử dụng mô hình riêng tư, tự lưu trữ, do Trung tâm Khoa học Dữ liệu Nghiên cứu Cornerstone lưu trữ và triển khai. Khả năng xử lý dữ liệu nội bộ của 4 Cornerstone Research bao gồm chạy các bộ xử lý đồ họa (GPU) hiện đại, phần cứng phức tạp cung cấp sức mạnh xử lý và bộ nhớ cần thiết để chạy LLM một cách hiệu quả. Cơ sở hạ tầng này—được xây dựng để giải quyết các vấn đề cần cân nhắc về bảo mật dữ liệu có thể phát sinh khi dựa vào các mô hình do bên thứ ba lưu trữ—cho phép phân tích dữ liệu văn bản một cách thực tế và an toàn trên quy mô lớn.
Một loạt các phương pháp tiếp cận có thể được sử dụng với LLM để phân tích văn bản tự do và rộng hơn là để hiểu cách công chúng cân nhắc các mục tiêu chính sách của Đạo luật AI. Phân tích này tuân theo một cách tiếp cận chung có thể áp dụng cho nhiều loại phân tích khác nhau. Điều này bao gồm các bước sau:
- Đã tải xuống toàn bộ bài đăng kể từ tháng 4 năm 2021 có chứa chuỗi văn bản “Đạo luật AI” hoặc thẻ bắt đầu bằng # “#AIAct”;
- Đã sử dụng LLM được lưu trữ riêng được triển khai cho máy chủ xử lý dữ liệu an toàn nội bộ của Cornerstone Research;
- Đã tạo một truy vấn (“lời nhắc”) để cung cấp cho mô hình các ví dụ về một số bài đăng và yêu cầu mô hình cung cấp phản hồi về cấu trúc dữ liệu cho mỗi bài đăng có chứa (i) chủ đề chính của bài đăng; và (ii) phân loại về cảm xúc của bài đăng là tích cực, trung lập hay tiêu cực.
Mặc dù quá trình này phức tạp về mặt kỹ thuật nhưng nó mang lại một kết quả đầu ra đơn giản: một tập dữ liệu chứa từng bài đăng và các nhãn xác định cảm xúc cũng như chủ đề được xác định của nó. Tập dữ liệu này cung cấp nhãn rõ ràng, có hệ thống cho từng bài đăng và có thể dễ dàng tổng hợp và phân tích để xác định các xu hướng chính.
Loại phân tích này được thiết kế để cung cấp cái nhìn tổng quan ở mức độ cao về các xu hướng. Khi làm như vậy, bản phân tích giả định—một cách hợp lý—rằng nội dung mọi người đăng phản ánh đúng quan điểm của họ về các mục tiêu khác nhau của quy định. Bất kỳ phân tích chi tiết hơn nào cũng cần phải xem xét các vấn đề như mức độ tin cậy của một bài đăng phản ánh các giá trị đã nêu.
Cảm xúc (sentiment) phát triển như thế nào?
Bằng cách sử dụng phân loại cảm xúc, người ta có thể quan sát cảm nhận chung đối với Đạo luật AI đã phát triển như thế nào.
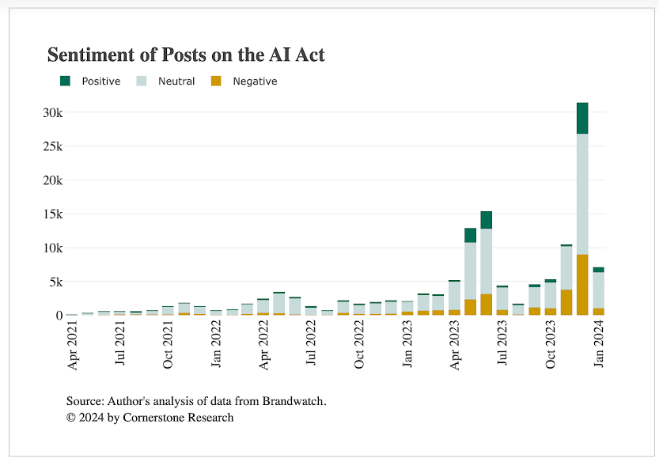
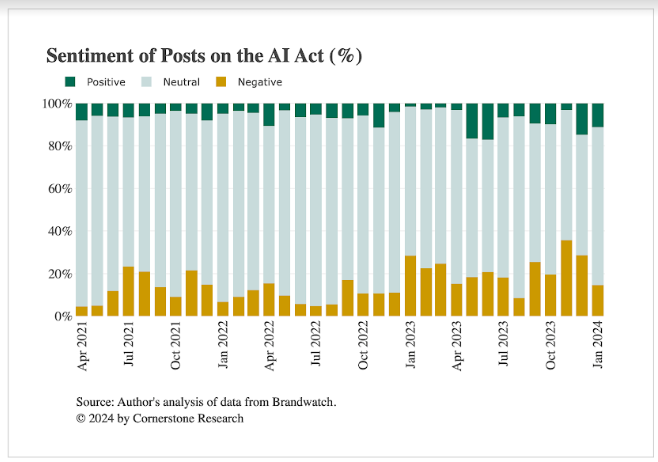
Một vài quan sát thú vị xuất hiện ở cấp độ cao này:
- Phần lớn các bài viết đều mang tính trung lập và không bày tỏ quan điểm cụ thể theo cách này hay cách khác. Phù hợp với phần lớn hoạt động xung quanh các chủ đề kỹ trị như vậy thường là sự trình bày thực tế về các sự phát triển, các bài đăng thường không đưa ra ý kiến về vấn đề này—ví dụ: các bài đăng có thể chỉ đơn giản là báo cáo về các cột mốc cụ thể đã đạt được hoặc trình bày liên kết đến các bài báo về các sự phát triển cụ thể. (1)
- Với sự phát triển hơn nữa, sức mạnh của ý kiến đã tăng lên theo thời gian. Trong khi đó, trong giai đoạn đầu của quá trình phát triển Đạo luật AI, phần lớn các bài đăng đều mang tính trung lập, thì gần đây, khoảng một phần ba đến một nửa số bài đăng đã thể hiện quan điểm không trung lập.
- Trong giai đoạn phân tích, tính trung bình, các bài viết tiêu cực nhiều hơn các bài viết tích cực. Điều này có thể là do thành kiến tiêu cực trên Internet — những người cảm thấy hài lòng phần nào với Đạo luật AI có thể sẽ không đăng về nó, trong khi những người cảm thấy tiêu cực về nó có thể cảm thấy cần phải viết điều gì đó. Theo thời gian, tính tiêu cực trong các loại bài đăng ngày càng gia tăng. Trong quý 4 năm 2022, 11,8% bài đăng là tiêu cực. Đến quý 4 năm 2023, con số này tăng lên 26,3%. Mặt khác, sự tích cực cũng tăng lên. Trong quý 4 năm 2022, tỷ lệ bài đăng tích cực là 2,7%, tăng lên 12,8% vào cuối năm 2023. Những xu hướng rộng này được khám phá ở cấp độ chi tiết hơn bên dưới bằng cách sử dụng những hiểu biết sâu sắc hơn từ mô hình LLM.
Trong khi ưu thế của tính trung lập và sức mạnh ngày càng tăng của các ý kiến theo thời gian phù hợp với những kỳ vọng trước đó, thì ưu thế của tiêu cực lại là điều đáng ngạc nhiên. Thật vậy, người ta mong đợi luật pháp nhằm mục đích mang lại sự an toàn và bảo vệ các quyền sẽ được công chúng bình luận đón nhận một cách thuận lợi. Điều này có thể là do các nhà phát triển AI hoặc thành viên cộng đồng doanh nghiệp—những người có nhiều khả năng bình luận hơn so với thành viên bình thường của công chúng—có thể cảm thấy rằng Đạo luật AI thể hiện sự vi phạm quy định. Mặc dù vấn đề này nằm ngoài phạm vi của phân tích này, nhưng nó đặt ra câu hỏi về cách phân chia cảm xúc giữa các nhóm cá nhân khác nhau và cách thể hiện chính xác cảm xúc tiêu cực hoặc tích cực.
Sự khác biệt cũng tồn tại ở khía cạnh địa lý. Theo trực giác, người ta có thể mong đợi các quốc gia được cho là có khuynh hướng chính trị mạnh mẽ hơn đối với thị trường tự do và đổi mới sẽ thể hiện nhiều tiêu cực hơn. Các nhà bình luận ở Anh và Đức thể hiện thái độ tiêu cực lớn hơn (22%–23%) đối với Đạo luật AI so với những người đồng hương của họ ở Bỉ (15%). Tuy nhiên, điều này không áp dụng phổ biến, trong đó Thụy Điển thể hiện mức độ tiêu cực cao nhất (28%). Tương tự, trên khắp Đại Tây Dương, các nhà bình luận Hoa Kỳ cho thấy mức độ bi quan tương tự như Anh và Đức ở mức 22%, trong khi các bài đăng của Canada cho thấy mức độ tiêu cực hơn đáng kể ở mức 27%. (2)
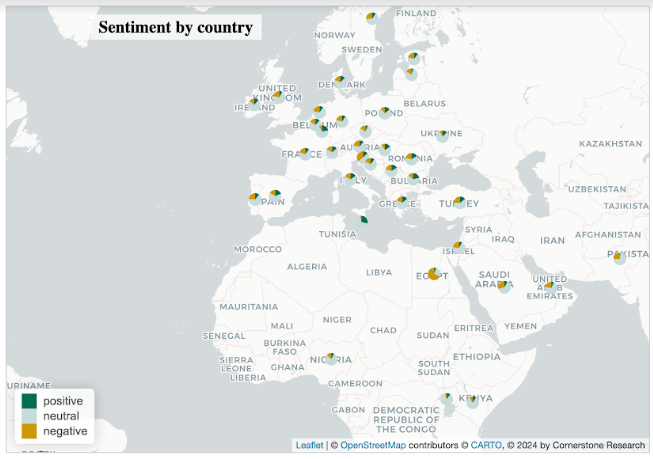
Lưu ý: Chỉ bao gồm dữ liệu cho các khu vực địa lý có hơn 50 bài đăng. Do hạn chế về nguồn dữ liệu, không phải tất cả các bài đăng đều có vị trí địa lý được xác định.
Mọi người đang đăng bài về cái gì?
Nhiều phương pháp kỹ thuật có thể được sử dụng để tóm tắt nội dung thảo luận. Thật vậy, với các mô hình AI hiện đại, người ta thậm chí có thể hỏi: “Bạn có thể tóm tắt cuộc thảo luận được không?” Mặc dù thú vị nhưng điều này để lại một chút mơ hồ trong phân tích do quy trình không rõ ràng để thu được một bản tóm tắt — phê bình “hộp đen” thông thường đối với các hệ thống AI. Ngoài ra, các nhà nghiên cứu có thể tiến hành một bài tập liên quan đến mô hình NLP để tạo nhãn ở cấp độ bài đăng riêng lẻ và sau đó sử dụng lý luận để phân tích xu hướng.
Quá trình tạo nhãn tóm tắt nội dung thường được gọi là “mô hình hóa chủ đề”. Mô hình hóa chủ đề là một nhiệm vụ NLP nhằm mục đích xác định các chủ đề hoặc chủ đề chính trong nội dung văn bản. Nó đã tồn tại như một lĩnh vực nghiên cứu trong nhiều năm; tuy nhiên, những phát triển gần đây về LLM cho phép loại bài tập này được thực hiện với độ chính xác cao hơn nhiều.
Sử dụng phương pháp LLM này xác định một số chủ đề trong tập dữ liệu. Vì các mô hình NLP không rõ ràng về những gì nên được coi là chủ đề có liên quan nên phạm vi kết quả rất rộng — phù hợp với tính đa dạng của các chủ đề đang được thảo luận. Tập dữ liệu trong bài viết này đã xác định hàng nghìn chủ đề, một số chủ đề rất không thường xuyên (ví dụ: “tự động sửa lỗi”, “sàng lọc cartel” và “thần học”) và một số chủ đề rất thường xuyên (ví dụ: “nhân quyền”, “giám sát” và “đổi mới”).
Các chủ đề chính xuất hiện—được hiển thị trong đám mây từ 7 ở trên —nói chung là nhất quán với những gì một người quan sát có hiểu biết mong đợi. Một số chủ đề khái niệm nổi bật: “đổi mới” là chủ đề được thảo luận phổ biến nhất, tiếp theo là “minh bạch”, “tuân thủ”, “nhân quyền”, “các quyền cơ bản”. Các chủ đề thú vị khác nổi lên là Quy định chung về bảo vệ dữ liệu hoặc GDPR (với các nhà bình luận so sánh với luật), ChatGPT (được cho là mô hình đã đẩy LLM trở thành phương tiện truyền thông chính thống), mô hình nền tảng, nhận dạng khuôn mặt, giám sát, đạo đức, nguồn mở, chính sách dự đoán, phân biệt đối xử, an toàn, cạnh tranh, quyền riêng tư và bản quyền.
Cảm xúc về những chủ đề này thay đổi như thế nào?
Đối với bất kỳ chủ đề nào trong số này, tập dữ liệu cho phép kiểm tra kỹ hơn xem cảm xúc là gì và nó phát triển như thế nào. Biểu đồ dưới đây phân tích sự thay đổi quan điểm đối với năm chủ đề liên quan đến nhiều lĩnh vực chính sách – cạnh tranh, đổi mới, quyền riêng tư, quyền và tính minh bạch.
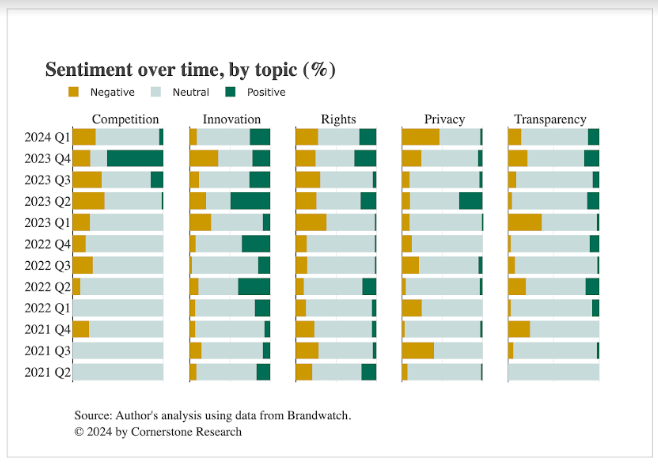
Trong giai đoạn phân tích, có rất ít bình luận tích cực về tác động của Đạo luật đối với cạnh tranh. Tâm lý tiêu cực chiếm ưu thế – cho thấy niềm tin chung rằng quy định về AI có thể có tác động tiêu cực đến cạnh tranh. Trong quý 4 năm 2023, tâm lý tích cực chiếm ưu thế áp đảo. Kiểm tra thủ công nhận thấy rằng đây chủ yếu là các bài đăng kỷ niệm các cuộc đàm phán hoàn tất về Đạo luật AI vào tháng 12 năm 2023.
Điều đáng ngạc nhiên là về chủ đề đổi mới, tâm lý lại tích cực hơn tiêu cực. Nhiều người ủng hộ Đạo luật AI đã khẳng định rằng trên thực tế, có thể có nhiều đổi mới hơn và tốt hơn do có các quy tắc được xác định rõ ràng trong lĩnh vực này và điều này được thể hiện qua tần suất đăng các bài đăng tích cực liên quan đến đổi mới.
Nói chung, người ta mong đợi sẽ thấy nhiều mặt tích cực hơn và ít tiêu cực hơn xung quanh các lĩnh vực mà Đạo luật AI hướng tới nhằm cải thiện—về quyền, quyền riêng tư và tính minh bạch. Điều này dường như không đúng. Mặc dù người ta thấy có nhiều sự tích cực hơn về quyền vào năm 2023 so với năm 2022, nhưng mức độ cảm nhận tiêu cực là đáng kể và kéo dài. Điều tương tự cũng đúng với các chủ đề về quyền riêng tư và minh bạch.
Ý nghĩa của nó là gì? Nếu phản hồi từ các bài bình luận trên internet được tin tưởng, thì điều này cho thấy các nhà lập pháp vẫn còn một số việc phải làm để thuyết phục công chúng rằng Đạo luật AI thực sự sẽ cung cấp các biện pháp bảo vệ mà nó hướng tới và các tác động đổi mới dự kiến sẽ có lợi.
Kết luận: đạt được những hiểu biết sâu sắc thông qua các phương pháp tiếp cận tự động thông minh
Văn bản là một nguồn thông tin rất phong phú—bằng cách khai thác nó một cách hiệu quả, các nhà nghiên cứu có thể rút ra những hiểu biết sâu sắc một cách có hệ thống và ở quy mô lớn từ nhiều nguồn khác nhau. Việc sử dụng LLM mới nhất cho phép phân tích các vấn đề thời sự như luật mới nhưng cũng có thể được sử dụng để xem xét và tóm tắt bằng chứng trong thủ tục tố tụng, làm phong phú thêm dữ liệu được sử dụng trong phân tích kinh tế hoặc mang lại hiệu quả trong cách các nhà kinh tế và luật sư làm việc.
(1) Việc kiểm tra thủ công các phân loại được chọn ngẫu nhiên đã được tiến hành để xác minh rằng các bài đăng được phân loại chính xác là trung lập, thay vì chỉ đơn giản là khó phân loại.
(2) Đúng như dự đoán, những quốc gia có tâm lý tiêu cực nhất cũng có tâm lý ít tích cực nhất, vì vậy điều ngược lại vẫn đúng.
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist