
Bạn đã bao giờ tự hỏi làm thế nào các trang web tin tức lớn có thể phân loại hàng ngàn bài báo mỗi ngày một cách nhanh chóng và chính xác? Bí mật nằm ở trí tuệ nhân tạo (AI) và xử lý ngôn ngữ tự nhiên (NLP), được ứng dụng để phân loại nội dung một cách tự động, giúp người đọc dễ dàng tìm kiếm và tiếp cận thông tin mình cần.
Bài viết này sẽ đưa bạn vào hành trình khám phá quy trình phân loại bài báo bằng NLP (classification), từ việc thu thập dữ liệu đến huấn luyện mô hình AI và cuối cùng là đánh giá hiệu suất. Bên cạnh đó, chúng ta sẽ cùng phân tích case study cụ thể với ví dụ minh họa và code Python thực tế.
Table of Contents
1. Thu thập dữ liệu
Bước đầu tiên là thu thập dữ liệu từ các bài báo. Dữ liệu có thể được thu thập từ nhiều nguồn, ví dụ như:
- Website: Các trang web tin tức thường cung cấp API hoặc cho phép tải xuống dữ liệu dạng RSS feed.
- Tập tin CSV: Dữ liệu có thể được lưu trữ trong một tập tin CSV, mỗi dòng chứa thông tin về một bài báo.
- Scraping: Sử dụng kỹ thuật web scraping để thu thập dữ liệu từ các trang web.
Ví dụ:
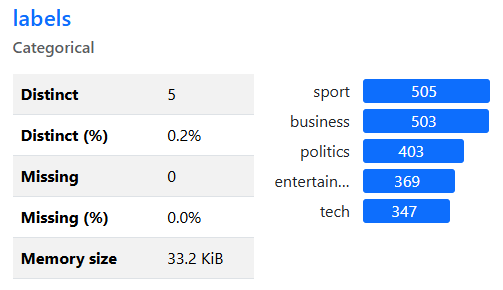
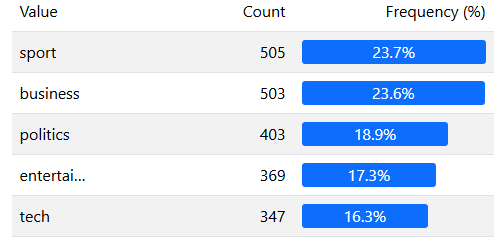
Giả sử chúng ta có một tập tin CSV chứa dữ liệu về các bài báo với cột “text” (nội dung bài báo) và cột “labels” (chủ đề bài báo).
| text | labels |
| Thị trường chứng khoán sôi động trong quý vừa qua | kinh tế |
| Đội tuyển bóng đá quốc gia giành chiến thắng | thể thao |
Ví dụ thực tế cho dataset về hơn 2000 bài báo BBC thu thập được: https://www.kaggle.com/datasets/jacopoferretti/bbc-articles-dataset/data . Vào trang này, bạn có thể download dataset về xem để tham khảo.
2. Kiểm tra và làm sạch dữ liệu
Sau khi thu thập dữ liệu, chúng ta cần kiểm tra và làm sạch dữ liệu để đảm bảo tính chính xác và nhất quán.
- Kiểm tra các giá trị thiếu: Dùng lệnh df.isnull().sum() để kiểm tra xem có giá trị nào bị thiếu trong cột “text” hay “labels” không. Theo Click Digital, việc thiếu dữ liệu có thể gây ảnh hưởng nghiêm trọng đến kết quả phân loại.
- Xóa các dòng trùng lặp: Dùng lệnh df.drop_duplicates(inplace=True) để loại bỏ các dòng trùng lặp. Nếu có nhiều dòng trùng lặp, mô hình AI sẽ bị nhầm lẫn và đưa ra kết quả không chính xác.
- Xử lý các ký tự đặc biệt: Loại bỏ các ký tự đặc biệt, khoảng trắng thừa, v.v.
- Chuyển đổi chữ hoa thành chữ thường: Giúp đảm bảo tính nhất quán trong dữ liệu.
3. Phân tích dữ liệu
Sau khi đã có bộ dữ liệu sạch, chúng ta có thể phân tích dữ liệu để hiểu rõ hơn về cấu trúc và nội dung của dữ liệu.
- Sử dụng ydata-profiling: Thư viện ydata-profiling giúp ta tạo ra một báo cáo phân tích dữ liệu chi tiết, bao gồm thống kê, biểu đồ, và phân tích dữ liệu cho các cột “text” và “labels”.
4. Chuẩn bị dữ liệu cho mô hình AI
Trước khi đưa dữ liệu vào mô hình AI, chúng ta cần chuẩn bị dữ liệu.
- Tách dữ liệu thành hai phần: Dữ liệu đầu vào (X) gồm cột “text” và nhãn mục tiêu (y) gồm cột “labels”.
- Chuyển đổi dữ liệu văn bản: Sử dụng TfidfVectorizer để chuyển đổi dữ liệu văn bản thành ma trận TF-IDF, giúp mô hình AI dễ dàng xử lý. Ma trận TF-IDF sẽ phản ánh tần suất xuất hiện của các từ trong mỗi bài báo, và trọng số của các từ sẽ dựa trên mức độ phổ biến của chúng trong toàn bộ tập dữ liệu.
- Mã hóa nhãn: Sử dụng LabelEncoder để mã hóa các nhãn mục tiêu thành các giá trị số, giúp mô hình AI dễ dàng học và dự đoán. Ví dụ, nhãn “kinh tế” có thể được mã hóa thành số 0, “thể thao” thành số 1, v.v.
5. Chia dữ liệu thành tập huấn luyện và tập kiểm tra
Chúng ta chia dữ liệu thành tập huấn luyện (80%) và tập kiểm tra (20%). Mô hình AI sẽ được huấn luyện trên tập huấn luyện và đánh giá hiệu suất trên tập kiểm tra.
6. Huấn luyện mô hình AI
Mô hình AI được sử dụng trong ví dụ này là hồi quy logistic, một thuật toán phổ biến trong phân loại. Mô hình được huấn luyện trên tập huấn luyện để học cách dự đoán nhãn mục tiêu từ dữ liệu đầu vào.
Code Python:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
7. Dự đoán và đánh giá hiệu suất
Sau khi huấn luyện, mô hình AI sẽ dự đoán nhãn mục tiêu cho tập kiểm tra. Chúng ta sử dụng độ chính xác để đánh giá hiệu suất của mô hình, cho biết tỷ lệ dự đoán chính xác.
Code Python:
y_pred = model.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
Kết quả
Độ chính xác của mô hình có thể đạt được 96.48% (trong ví dụ về hơn 2000 bài báo BBC đề cập ở mục 1). Có thể thấy rằng, mô hình AI đã phân loại bài báo một cách rất hiệu quả, cho thấy sức mạnh của AI trong xử lý ngôn ngữ tự nhiên.
Nhận xét
Phân loại bài báo là một ví dụ điển hình cho thấy sự ứng dụng rộng rãi của AI trong lĩnh vực xử lý ngôn ngữ tự nhiên, đặc biệt là trong việc tự động hóa các tác vụ liên quan đến phân loại nội dung, giúp tiết kiệm thời gian và nâng cao hiệu quả. AI có thể xử lý lượng lớn dữ liệu một cách nhanh chóng và chính xác, giúp người đọc dễ dàng tìm kiếm và tiếp cận thông tin mình cần.
Sự phát triển của AI và NLP đang ngày càng mở rộng phạm vi ứng dụng trong nhiều lĩnh vực, từ phân loại văn bản, dịch thuật, đến chatbot và trợ lý ảo. AI đã trở thành một công cụ hữu ích cho các doanh nghiệp, giúp họ tự động hóa các quy trình, tối ưu hóa hoạt động và nâng cao hiệu quả.
So sánh các phương pháp phân loại bài báo:
| Phương pháp | Ưu điểm | Nhược điểm |
| Phân loại thủ công | Độ chính xác cao | Tốn thời gian, công sức |
| Phân loại tự động (AI) | Nhanh chóng, hiệu quả | Độ chính xác có thể thấp hơn phân loại thủ công |
Kết luận
AI và NLP đang ngày càng được ứng dụng rộng rãi trong nhiều lĩnh vực, từ phân loại văn bản, dịch thuật, đến chatbot và trợ lý ảo. Hãy cùng chờ đợi những ứng dụng đột phá của AI trong tương lai, mang đến những trải nghiệm mới cho cuộc sống của chúng ta.
Bảng tổng hợp bài viết
| Tiêu đề | Nội dung |
| Thu thập dữ liệu | Đọc dữ liệu từ tập tin CSV, mỗi dòng chứa thông tin về một bài báo |
| Kiểm tra và làm sạch dữ liệu | Kiểm tra các giá trị thiếu, xóa các dòng trùng lặp, xử lý các ký tự đặc biệt, chuyển đổi chữ hoa thành chữ thường |
| Phân tích dữ liệu | Sử dụng ydata-profiling để phân tích dữ liệu |
| Chuẩn bị dữ liệu cho mô hình AI | Tách dữ liệu thành X và y, chuyển đổi dữ liệu văn bản, mã hóa nhãn |
| Chia dữ liệu | Chia dữ liệu thành tập huấn luyện và tập kiểm tra |
| Huấn luyện mô hình AI | Huấn luyện mô hình hồi quy logistic trên tập huấn luyện |
| Dự đoán và đánh giá hiệu suất | Dự đoán nhãn mục tiêu cho tập kiểm tra, đánh giá độ chính xác |
| Nhận xét | Nêu bật sự ứng dụng của AI trong xử lý ngôn ngữ tự nhiên |
| Nhận xét bổ sung | Nêu bật sự phát triển của AI và NLP trong nhiều lĩnh vực |
| Kết luận | AI và NLP đang ngày càng được ứng dụng rộng rãi |
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist