
Table of Contents
Language Model as Agents
What are agents?
Agents có thể được hiểu là bất kỳ thứ gì có khả năng nhận thức môi trường thông qua các cảm biến và tác động lên môi trường thông qua các cơ cấu chấp hành. Trong sơ đồ này, bạn có thể thấy agent sẽ nhận thông tin từ môi trường và thực hiện các hành động dựa trên thông tin đó. Agents có thể có các khả năng, kiến thức, mục tiêu hoặc sở thích nhất định.
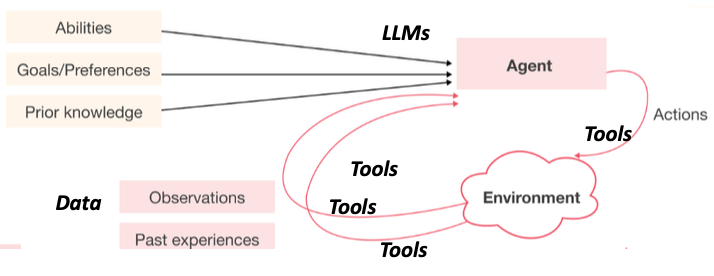
Vì chủ đề hôm nay là về các agent trong mô hình ngôn ngữ, chúng ta thường sử dụng các mô hình ngôn ngữ lớn làm agent. Các công cụ đã được đề cập có thể được sử dụng như các cảm biến hoặc cơ cấu chấp hành. Ví dụ, việc phát nhạc có thể được xem như một cơ cấu chấp hành. Các khả năng, kiến thức trước đó hoặc kinh nghiệm có thể được coi là dữ liệu hoặc dữ liệu huấn luyện cho mô hình ngôn ngữ của bạn.
How to get started in LLM Agents?
Để bắt đầu với các agent trong mô hình ngôn ngữ, tôi sẽ trình bày bốn giai đoạn để xây dựng một LLM Agent. Đầu tiên, tôi sẽ đề cập đến một số nhiệm vụ và ứng dụng. Thứ hai, tôi sẽ giới thiệu một số phương pháp không cần huấn luyện để xây dựng các agent, giúp bạn có thể sử dụng với các mô hình dựa trên API. Tiếp theo là môi trường đánh giá và Benchmark, một chủ đề cực kỳ quan trọng trong nghiên cứu. Cuối cùng, tôi sẽ nói ngắn gọn về một số phương pháp huấn luyện để cải thiện các agent. Vì đây là một lĩnh vực đang phát triển, một số phương pháp huấn luyện có thể chưa phải là tốt nhất.
Tasks and Applications for LLM Agents
Why do we want agents?
Hãy tưởng tượng nếu mọi việc có thể được thực hiện chỉ bằng cách nói chuyện, giống như cách mà các “human agents” (tác nhân con người) hoạt động. Ví dụ, bạn nói chuyện với một “real estate agent” để mua nhà.
How do People Interact with Computers?
Hiện tại, khi tương tác với máy tính, chúng ta thường sử dụng giao diện đồ họa hoặc viết mã bằng tay qua bàn phím và chuột. Nhưng trong tương lai, nếu mọi thứ có thể được thực hiện chỉ bằng cách nói chuyện với các trợ lý ảo như Alexa hay Google Assistant, thì điều đó sẽ tiết kiệm thời gian, tự nhiên hơn, dễ tiếp cận và không cần phải vượt qua các “learning curve” (đường cong học tập) của các chương trình phức tạp.
Hiện nay, có một số agent giúp thực hiện các nhiệm vụ thông qua giao diện ngôn ngữ tự nhiên, chẳng hạn như Siri, Google Assistant, và Alexa. Ví dụ, bạn có thể đặt báo thức, và đó chính là một agent vì nó thực hiện việc đặt báo thức cho bạn. Ngoài ra, còn có các công cụ lập trình ngôn ngữ tự nhiên như GitHub Copilot, giúp bạn viết mã. Bạn chỉ cần nói “I want to sort my list in descending order” và nó sẽ tạo ra mã thực hiện điều đó cho bạn.
Tool Integrations into Chatbots
Nhiều người hiện nay sử dụng Chat GPT trong cuộc sống hàng ngày. Khi tính năng tích hợp plugin được giới thiệu, công cụ này đã trở nên mạnh mẽ hơn. Các tích hợp này cho phép chatbot thực hiện nhiều tác vụ hữu ích như đặt lịch hẹn PRS hoặc tạo đơn hàng trên Instacart.
Robots
Trong lĩnh vực robot, một ứng dụng tiềm năng của các agent là điều hướng bằng ngôn ngữ tự nhiên. Ví dụ, agent có thể quan sát môi trường xung quanh giống như trong Google Street View và thực hiện các chỉ dẫn ngôn ngữ tự nhiên để di chuyển qua các con phố.
Một tập dữ liệu phổ biến cho nhiệm vụ này là Alward, nơi agent được đặt trong một môi trường mô phỏng và nhận mô tả bằng văn bản, chẳng hạn như “bạn đang ở giữa phòng, xung quanh có giường và tủ ngăn kéo”.
Nhiệm vụ của agent là tìm và tương tác với một đối tượng cụ thể, ví dụ như đồng hồ báo thức trên bàn. Mô hình ngôn ngữ lý tưởng sẽ dự đoán hành động cần thực hiện, chẳng hạn như di chuyển đến bàn, và sau đó cập nhật quan sát khi đến vị trí mới. Qua đó, ta có thể thấy cách agent tương tác với môi trường xung quanh thông qua việc quan sát và thực hiện hành động.
Games
Trong lĩnh vực trò chơi, có nhiều ứng dụng và tiêu chuẩn đánh giá thú vị. Một ví dụ điển hình là Mind Dojo, nơi người dùng có thể tạo ra một agent có khả năng lắng nghe hướng dẫn bằng ngôn ngữ tự nhiên và thực hiện các nhiệm vụ trong trò chơi Minecraft. Ngoài ra, DeepMind gần đây đã phát triển một công trình mang tên Sema, cho phép người dùng đưa ra hướng dẫn bằng ngôn ngữ tự nhiên để lập trình một trò chơi bắn thiên thạch, giúp tự động bắn hạ thiên thạch trong trò chơi.
Software Development
Trong lĩnh vực phát triển phần mềm, các agents trong mô hình ngôn ngữ đang được ứng dụng ngày càng rộng rãi. Gần đây, một startup tên là Devon đã phát triển một “kỹ sư phần mềm AI”. Hệ thống này bao gồm một trình soạn thảo mã, một terminal để thực thi lệnh, và một trình duyệt web để tìm kiếm tài liệu.
Lý tưởng nhất, nếu mọi thứ được tự động hóa, bạn chỉ cần đưa ra một chỉ dẫn tự nhiên, chẳng hạn như “hoàn thành bài tập 711 cho tôi”, và agent sẽ thực hiện công việc đó trong không gian làm việc này. Trong kịch bản này, hệ thống sẽ quan sát chuỗi lệnh bao gồm terminal, trình duyệt web, và trình soạn thảo mã. Các hành động có thể thực hiện bao gồm: ra lệnh cho terminal, tìm kiếm trên trình duyệt web, hoặc viết mã trong trình soạn thảo.
UI Automation
Trong lĩnh vực tự động hóa giao diện người dùng (UI), có thể thực hiện các tác vụ như duyệt web, phát nhạc, hoặc phóng to thu nhỏ giao diện. Những thao tác này liên quan đến việc điều hướng giao diện đồ họa người dùng (GUI).
Training-free Methods for Building Agents
Vừa rồi, chúng ta đã có cái nhìn tổng quan về các nhiệm vụ và ứng dụng của agents, câu hỏi đặt ra là: liệu chúng ta có thể phát triển các phương pháp để xây dựng những LM agents hiệu quả hay không? Với một mô hình ngôn ngữ mạnh mẽ trong tay, chủ đề này trở nên vô cùng hấp dẫn. Để bắt đầu, tôi sẽ giới thiệu một số phương pháp không cần huấn luyện để phát triển các agent này.
Trong phần này, chúng ta sẽ khám phá cách biến một mô hình ngôn ngữ thành một agent thông minh có khả năng tương tác với môi trường. Để làm được điều này, một agent cần có khả năng nhận diện và xử lý các quan sát từ môi trường hiện tại, có thể là văn bản, hình ảnh, âm thanh hoặc dữ liệu có cấu trúc.
Quan sát từ môi trường
Một agent thường nhận đầu vào từ nhiều loại dữ liệu khác nhau. Ví dụ, trong một trò chơi, agent có thể nhận dữ liệu từ văn bản mô tả môi trường xung quanh, hình ảnh chụp màn hình hiện tại, hoặc âm thanh để nhận biết những gì đang xảy ra xung quanh mà không thể nhìn thấy trên màn hình. Đối với các ứng dụng web, dữ liệu có thể là cấu trúc HTML của trang web.
Khả năng lập kế hoạch và suy luận
Để thực hiện các nhiệm vụ phức tạp, mô hình ngôn ngữ cần có khả năng lập kế hoạch và suy luận. Một trong những phương pháp phổ biến là “Chain of Thought” (Chuỗi suy nghĩ), cho phép mô hình tạo ra các bước suy luận để thực hiện nhiệm vụ. Ví dụ, nếu nhiệm vụ là đặt một lọ tiêu lên ngăn kéo, mô hình sẽ suy luận rằng cần tìm lọ tiêu trước, sau đó mới đặt nó lên ngăn kéo.
Khả năng sử dụng công cụ
Ngoài việc lập kế hoạch và suy luận, mô hình ngôn ngữ cần có khả năng tương tác với môi trường thông qua các hành động. Điều này đòi hỏi mô hình phải tạo ra các lệnh hành động có thể thực thi, như gọi API để thay đổi trạng thái của môi trường và nhận lại quan sát mới để tiếp tục quá trình.
Một ví dụ thực tế là sử dụng mô hình ngôn ngữ để quyết định có nên đi leo núi hay không. Mô hình có thể gọi API để lấy thông tin thời tiết tại vị trí hiện tại, sau đó đưa ra quyết định dựa trên dữ liệu thời tiết nhận được.
Khi có nhiều API, việc cung cấp tất cả thông tin cho mô hình có thể vượt quá khả năng xử lý. Một giải pháp là sử dụng bộ nhớ ngoài để truy vấn và chỉ cung cấp những API cần thiết nhất dựa trên ngữ cảnh hiện tại.
Tạo mã để thực thi nhiệm vụ
Một cách tiếp cận khác là để mô hình ngôn ngữ tạo mã lập trình để thực hiện nhiệm vụ. Ví dụ, mô hình có thể tạo mã Python để lên lịch một cuộc họp, sau đó thực thi mã này để hoàn thành nhiệm vụ.
Evaluation Environment and Benchmark
Evaluation of LLM Agents
Đầu tiên, cần nhấn mạnh rằng việc đánh giá các LLM agent là một thách thức lớn. Nhiều nghiên cứu hiện tại sử dụng các môi trường đơn giản và các nhiệm vụ cơ bản, dẫn đến việc hiệu suất dễ dàng đạt đến mức bão hòa. Ví dụ, khi yêu cầu ChatGPT kiểm tra thời tiết để quyết định có nên đi hiking hay không, hoặc đặt lịch họp qua Google Calendar API, các tác vụ này đều rất đơn giản và dễ dàng đạt độ chính xác 100%. Tuy nhiên, điều này không phản ánh được tiến bộ thực sự trong nghiên cứu về các LLM agent.
Các benchmark đánh giá hiện tại thường là môi trường không trạng thái (stateless) và không tương tác. Ví dụ, “mind to web” tập trung vào việc chuyển đổi các trang web qua các hành động cụ thể và đánh giá dựa trên độ chính xác của chuỗi hành động. Tuy nhiên, cách đánh giá này có thể không lý tưởng vì nó không cho phép sự linh hoạt trong thứ tự thực hiện các hành động, dẫn đến việc bỏ lỡ những cơ hội mà agent thực hiện đúng nhưng không theo thứ tự đã định trước.
Ngoài ra, còn có các môi trường tương tác nhưng thường là ngắn hạn (short Horizon), như “webshop” – một phiên bản đơn giản hóa của Amazon. Trong môi trường này, các tác vụ thường chỉ yêu cầu một vài bước để hoàn thành, ví dụ như nhập “I love 711” vào ô văn bản và nhấn submit. Mặc dù các môi trường này cung cấp sự tương tác, nhưng chúng vẫn khá đơn giản và không phản ánh được độ phức tạp của các tình huống thực tế.
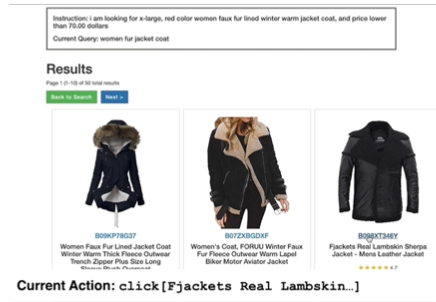
Keys to Agent Benchmarks
Trong việc xây dựng các benchmark cho agent, có một số yếu tố quan trọng cần xem xét. Đầu tiên, cần có một môi trường tương tác, vì nếu không có môi trường, việc đánh giá chỉ dừng lại ở việc kiểm tra xem hành động có đúng hay không, mà không xem xét kết quả thực thi cuối cùng.
Thứ hai, cần có sự đa dạng trong chức năng. Nếu chỉ tập trung vào một lĩnh vực như shopping, có nguy cơ là sẽ “overfit” vào chức năng đó. Nội dung cũng cần phong phú và thực tế để giúp agent có thể thích ứng tốt hơn với các trang web hiện đại, từ đó cải thiện khả năng chuyển giao hiệu suất từ các benchmark sang các trang web thực tế.
Môi trường cần phải tương tác, dễ mở rộng và có thể tái tạo. Việc tái tạo là rất quan trọng trong cộng đồng nghiên cứu, vì vậy chúng ta không nên sử dụng các trang web trực tiếp làm môi trường thử nghiệm do chúng thường xuyên thay đổi. Chẳng hạn, nếu bạn đạt 90% độ chính xác hôm qua, hôm nay có thể chỉ còn 20% vì các trang web đã thay đổi.
Chúng ta cũng nên hướng tới các nhiệm vụ dài hạn với độ khó đủ để thách thức agent. Việc kết hợp nhiều trang web, như “Reddit” để tìm kiếm đánh giá, cũng là một điểm cộng. Cuối cùng, cần có các chỉ số đánh giá đáng tin cậy để khuyến khích đạt được mục tiêu cuối cùng thay vì chỉ thỏa mãn một phần, đồng thời thúc đẩy agent thực hiện nhiệm vụ đúng cách thay vì chỉ làm theo các hành động được cung cấp.
WebArena Environment Design
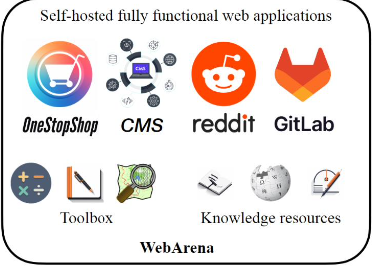
Trong lĩnh vực phát triển web, một trong những công trình mới nhất là Arena, một môi trường nhằm đáp ứng các yêu cầu đã được đề ra trước đó, cụ thể là một “setbox internet”. Đây là một giải pháp mã nguồn mở, sẵn sàng cho sản xuất, cho phép triển khai các trang web và dữ liệu từ các trang web thực tế phổ biến. Chúng tôi thực hiện việc thu thập dữ liệu từ các trang như Amazon và đưa vào một trang web giả lập Amazon.
Arena cũng dễ dàng phân phối nhờ vào việc sử dụng Docker, giúp cho việc tái tạo môi trường trở nên thuận tiện hơn. Mặc dù việc lựa chọn trang web có thể bị giới hạn, chúng ta cố gắng làm cho nó đa dạng bằng cách bao gồm nhiều loại trang web khác nhau, như một trang web mua sắm, một trang quản lý nội dung, và một diễn đàn tương tự như Reddit. Ngoài ra, chúng tôi còn tích hợp Wikipedia và một số công cụ khác, bao gồm cả bản đồ, trong bộ công cụ đánh giá này.
Collecting Realistic Intents
Việc thu thập các ý định thực tế của người dùng là rất quan trọng. Một cách hiệu quả để thu thập những ý định này là kiểm tra lịch sử trình duyệt của chính chúng ta hoặc của người khác. Sau đó, chúng ta có thể phân loại chúng thành ba loại chính:
- Tìm kiếm thông tin: Phần lớn hoạt động trên internet của chúng ta là để tìm kiếm thông tin. Ví dụ, khi bạn muốn biết lần cuối cùng mình mua dầu gội là khi nào để nhắc nhở bản thân.
- Điều hướng: Đây là những hoạt động giúp chúng ta tìm đường hoặc truy cập vào các tài nguyên cụ thể. Ví dụ, bạn muốn kiểm tra các yêu cầu hợp nhất (merge requests) được giao cho mình khi bắt đầu một ngày làm việc mới.
- Thao tác nội dung và cấu hình: Những tác vụ này thường yêu cầu bạn thay đổi môi trường ở một mức độ nào đó. Như đã thảo luận trước đây, một agent không chỉ có thể thu thập thông tin từ môi trường mà đôi khi còn phải thực hiện các hành động ngược lại. Ví dụ, nếu bạn muốn đăng câu hỏi “Có cần thiết phải có xe hơi ở New York City không?” trên một subreddit mà bạn nghĩ sẽ nhận được câu trả lời, bạn đang thực hiện một thay đổi nhỏ trong môi trường trực tuyến của mình.
Việc hiểu rõ và phân loại các ý định này giúp cải thiện khả năng tương tác và đáp ứng của các hệ thống thông minh.
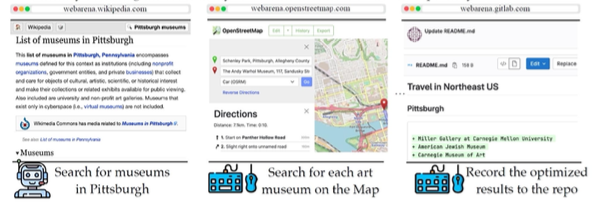
Example Tasks in WebArena
Dưới đây là một ví dụ về một nhiệm vụ phức tạp trong một bài kiểm tra: tạo kế hoạch thăm các bảo tàng ở Pittsburgh với khoảng cách lái xe tối thiểu, bắt đầu từ Shy Park và ghi lại thứ tự trong kho lưu trữ du lịch Đông Bắc Hoa Kỳ. Nhiệm vụ này yêu cầu nhiều bước, bao gồm tìm kiếm thông tin trên nhiều trang web. Đầu tiên, bạn cần tìm kiếm các bảo tàng ở Pittsburgh, có thể sử dụng Google hoặc Wikipedia. Sau đó, bạn tìm kiếm từng bảo tàng nghệ thuật trên phần mềm bản đồ và cuối cùng kiểm tra khoảng cách lái xe tối thiểu. Nhiệm vụ này đòi hỏi cả khả năng suy luận toán học để thu thập và tối ưu hóa khoảng cách lái xe, sau đó sắp xếp chúng trong kho lưu trữ.
Outcome/ Execution-based Evaluation
Trong quá trình thực hiện các tác vụ phức tạp, chúng ta không nên chỉ dựa vào đánh giá dựa trên chuỗi hành động. Mục tiêu của chúng ta là xác thực trực tiếp tính đúng đắn của kết quả thực thi. Ví dụ, câu hỏi “Lần cuối tôi mua dầu gội là khi nào?” có thể được trả lời trực tiếp bằng một ngày cụ thể, vì chúng ta đã biết trước dữ liệu có trong bộ đánh giá. Đối với những câu hỏi phức tạp hơn, chẳng hạn như “Có cần thiết phải có ô tô ở New York City không?”, chúng ta cần kiểm tra nội dung trong trang web hoặc tài liệu HTML để xác nhận. Những công cụ xác thực này có thể được xem như các bài kiểm tra đơn vị trong phát triển phần mềm, chỉ kiểm tra kết quả cuối cùng của môi trường để đảm bảo tính chính xác, từ đó giảm bớt sự phụ thuộc vào việc kiểm tra từng hành động.
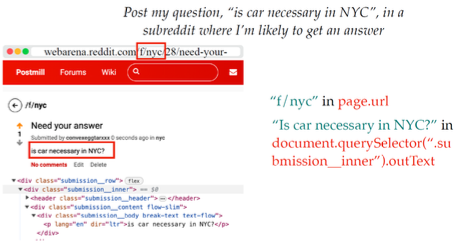
Observation & Action Space
Trong các tác vụ liên quan đến không gian quan sát và hành động, có thể sử dụng nhiều mô hình khác nhau. Bạn có thể chụp ảnh màn hình của trang web hoặc sử dụng không gian văn bản như mã nguồn HTML thô. Ngoài ra, có thể sử dụng phiên bản có cấu trúc hơn gọi là “cây truy cập” (accessibility tree), một cấu trúc dạng cây để biểu diễn cấu trúc của trang web. Đối với không gian hành động, chúng ta có thể sử dụng bàn phím để nhập liệu hoặc chuột để nhấp, di chuột và cuộn, cũng như sử dụng trình duyệt để quay lại trang trước.
Prompting LLM as Agent
Trong bài viết này, chúng ta đã thảo luận về việc sử dụng phương pháp gợi ý và học từ ngữ cảnh với ít ví dụ (Few-shot in-context learning) để cung cấp hướng dẫn tổng quát và một vài ví dụ minh họa. Để đánh giá hiệu suất của GPT-4 trong các nhiệm vụ phức tạp, chúng ta sẽ cung cấp cho GPT-4 một số hướng dẫn cụ thể. Chúng ta giới thiệu nó như một công cụ trí tuệ nhân tạo tự động và mô tả không gian quan sát mà nó sẽ làm việc. Chúng ta cũng chỉ ra các hành động mà nó có thể thực hiện và cung cấp một số ví dụ minh họa.
You are an autonomous intelligent agent tasked with navigating a web browser. You will be given web-based tasks. These tasks will be accomplished through the use of specific actions you can issue.
You can observe the following information:
…
You can do the following actions:
…
…
Không gian quan sát được mô tả như một cấu trúc dạng cây, là phiên bản đã được lọc của HTML, đại diện cho trang web. Thông tin bao gồm URL, mô tả nhiệm vụ và ví dụ về đầu ra. Chúng ta áp dụng phương pháp suy luận theo chuỗi tư duy, từng bước chỉ ra những gì cần làm và hành động, dựa trên không gian hành động đã được cung cấp trước đó. Các hành động này là những gì mà hệ thống có thể thực hiện trong môi trường đã định.

WebArena is Challenging
Bạn có thể thấy WebArena là một thách thức lớn. Khi yêu cầu con người thực hiện các nhiệm vụ này, họ có thể đạt độ chính xác khoảng 78% trong vòng 2 phút. Tuy nhiên, với các mô hình ngôn ngữ tiên tiến như GPT-3.5 hay GPT-4, ngay cả khi sử dụng các kỹ thuật prompt nâng cao, chỉ có thể giải quyết khoảng 14% bài kiểm tra.
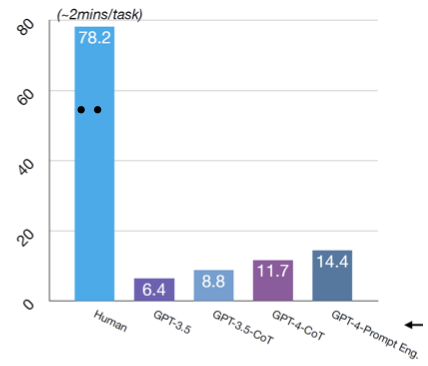
Mặc dù phương pháp “chain of thought” có thể hỗ trợ, nhưng lợi ích mang lại vẫn còn hạn chế và GPT-4 vẫn kém xa so với hiệu suất của con người. Kỹ thuật prompt thường nhấn mạnh sự nhạy cảm của các mô hình lớn đối với những thay đổi nhỏ trong hướng dẫn, và đôi khi việc này cũng không hề đơn giản.
Failures: Not Knowing How
Trong một số trường hợp thất bại của mô hình ngôn ngữ, đôi khi mô hình không biết nên nhấn nút nào. Ví dụ, khi yêu cầu “hiển thị cho tôi những khách hàng đã bày tỏ sự không hài lòng về một chiếc áo khoác có khóa kéo”, con người có thể dễ dàng nhận ra cần truy cập trang sản phẩm trong danh mục và kiểm tra đánh giá, hoặc vào phần đánh giá và tìm kiếm áo khoác đó. Tuy nhiên, mô hình như GPT-4 có thể thiếu kiến thức thông thường và có thể chuyển hướng sai, như vào phần khách hàng. Điều này cho thấy mô hình ngôn ngữ chưa có khả năng suy luận hoặc lập kế hoạch tốt khi thiếu thông tin cơ bản.
Failures: Not Being Accurate
Trong quá trình sử dụng các mô hình ngôn ngữ, đôi khi chúng có thể không chính xác. Ví dụ, khi bạn yêu cầu nhập ngày đến hạn, mô hình có thể nhập sai định dạng. Nếu trang web không được thiết kế tốt, quá trình này có thể bị dừng lại do định dạng không chính xác. Lý tưởng nhất là bạn nên sử dụng các công cụ kiểm tra trạng thái như vdet. Tuy nhiên, đôi khi mô hình ngôn ngữ có thể tự động tìm cách nhập văn bản mà không cần sự can thiệp của người dùng.
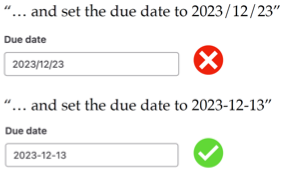
Failures: Trivial Errors
Trong bài báo nghiên cứu, chúng ta nhận thấy rằng các lỗi nhỏ nhặt có thể gây ra vấn đề lớn. Ví dụ, với mô hình GPT-4, khoảng 21% ví dụ gặp lỗi do việc gõ lặp lại. Điều này có thể liên quan đến hiện tượng “hallucination” trong các mô hình ngôn ngữ lớn, khi chúng tự động nhập một loạt các từ không liên quan như “DMV area” nhiều lần.
Ngoài ra, có những lỗi không hề đơn giản. Một ví dụ thú vị là khi yêu cầu mô hình GPT-4 thực hiện tác vụ trên trang GitLab, nó không hiểu từ “myself” và chỉ nhập từ này như một chuỗi ký tự. Thực tế, mô hình cần phải xác định danh tính của người dùng và nhập “me” hoặc tên người dùng của chính nó vào trường này. Điều này cho thấy sự phức tạp trong việc xử lý ngữ cảnh và danh tính cá nhân của các mô hình ngôn ngữ lớn.
Training Methods for Improving Agents
Trong phần này, tôi sẽ đề cập đến một số phương pháp huấn luyện để cải thiện hiệu suất của các agent. Trước đó, chúng ta đã thảo luận về các ứng dụng, cũng như một số kỹ thuật prompt và các tiêu chuẩn đánh giá tiên tiến. Mặc dù đã có môi trường thử nghiệm và áp dụng các kỹ thuật như “Chain of Thought prompting”, nhưng hiệu suất vẫn chưa đạt yêu cầu.
Learning of LLM Agents
Chủ đề chính của phần này là các phương pháp học cho LLM agents. Tôi sẽ tập trung vào ba loại hình học chính:
- Học trong ngữ cảnh (In-context learning): Một số người có thể cho rằng đây chỉ là gợi ý, nhưng việc cung cấp các ví dụ minh họa tốt hơn có thể giúp khai thác tối đa phương pháp này.
- Tinh chỉnh có giám sát (Supervised fine-tuning): Phương pháp này dựa trên việc học từ các chuyên gia. Nếu có dữ liệu chất lượng về cách con người thực hiện một nhiệm vụ, chúng ta có thể sử dụng chúng để cải thiện mô hình.
- Học tăng cường (Reinforcement learning): Đối với các tác nhân tương tác với môi trường, học tăng cường là một kỹ thuật phổ biến. Nếu có một môi trường đủ tốt, mô hình có thể học từ chính môi trường đó.
In-context Learning
Học trong ngữ cảnh (In-context Learning) là một phương pháp mà mô hình ngôn ngữ có thể thực hiện nhiệm vụ chỉ bằng cách điều chỉnh theo các ví dụ đầu vào và đầu ra mà không cần tối ưu hóa các tham số khác. Điều này thường xảy ra khi chúng ta không có quyền truy cập vào các tham số hoặc việc huấn luyện quá tốn kém. Tuy nhiên, đây vẫn là một phương pháp phổ biến trong học máy.
Ví dụ, khi thực hiện các bài kiểm tra trên nền tảng web, chúng ta cung cấp một số ví dụ về quan sát và hành động cần thực hiện cho một nhiệm vụ cụ thể.

Trong học trong ngữ cảnh, chúng ta có thể đưa ra các ví dụ về quan sát của người dùng, chẳng hạn như một trang web được biểu diễn dưới dạng cây tài liệu HTML đã được rút gọn. Phần ví dụ của assistant sẽ đóng vai trò như nhãn đầu ra, thể hiện cách thực hiện suy luận theo chuỗi và định dạng hành động cần thực hiện.
Với việc cung cấp hướng dẫn rõ ràng, không gian hành động và một số ví dụ điển hình về cặp quan sát-hành động, mô hình ngôn ngữ có thể tự động nhận diện định dạng và tạo ra các hành động theo định dạng đã chỉ định. Học trong ngữ cảnh đôi khi rất hiệu quả trong việc điều chỉnh mô hình ngôn ngữ theo yêu cầu cụ thể của bạn.
Supervised Fine-tuning
Để tinh chỉnh có giám sát, đầu tiên chúng ta thu thập một lượng lớn dữ liệu từ các chuyên gia thông qua việc thích ứng của con người. Ví dụ, bạn có thể có các cặp nhiệm vụ như quan sát ý định, hành động, và sau đó tối ưu hóa chúng bằng cách sử dụng hàm mất mát cross-entropy. Nhiều nghiên cứu hiện tại cố gắng tối ưu hóa các mô hình ngôn ngữ bằng cách thu thập các chú thích từ con người.
task_intent, [(obs_1, action_1), …,(obs_N, action_N)]
Phương pháp này hoạt động rất hiệu quả nhưng đòi hỏi nhiều tài nguyên và không thể học được nhiều từ các chuỗi hành động thất bại. Chẳng hạn, nếu bạn có một chuỗi hành động thành công và một chuỗi thất bại, bạn có thể không tận dụng được chuỗi thất bại, ngay cả khi chỉ có bước cuối cùng là sai. Có một số kỹ thuật tăng cường dữ liệu, ví dụ như trong trò chơi Minecraft, bạn có thể thực hiện tăng cường dữ liệu dựa trên video YouTube, bài viết Wikipedia, hoặc các thảo luận trên Reddit.
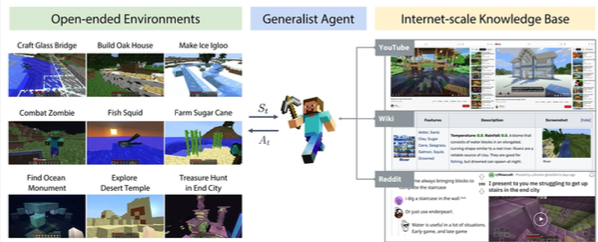
Reinforcement Learning
Trong lĩnh vực học tăng cường, hiện nay có nhiều phương pháp mới đang được nghiên cứu và phát triển. Trước đây, một số nghiên cứu tập trung vào việc học từ phản hồi của con người. Tuy nhiên, hiện tại, có những hướng đi mới không cần đến phản hồi từ con người. Thay vào đó, chúng ta có thể thay thế các phần thưởng (rewards) bằng môi trường thực tế.
Ví dụ, khi bạn có quyền truy cập vào một môi trường như Web Arena, việc xác định một nhiệm vụ có thành công hay không có thể được thực hiện tự động thông qua môi trường đó. Điều này mang lại một dạng phản hồi tự nhiên từ môi trường, giúp cải thiện quá trình học tập của mô hình.
Nếu bạn quan tâm đến các nghiên cứu đang diễn ra trong lĩnh vực này, có thể tham khảo thêm các bài báo (Ouyang et al. 2022, Song et al. 2024, Yao et al. 2023) trong phần tài liệu tham khảo dưới đây để có cái nhìn sâu hơn về những tiến bộ mới nhất.
Resources
- https://phontron.com/class/anlp2024/lectures/#language-agents-march-28
- TroVE: Inducing Verifiable and Efficient Toolboxes for Solving Programmatic Tasks Wang et al. 2024
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models Wei et al. 2022
- Toolformer: Language Models Can Teach Themselves to Use Tools
- ReAct: Synergizing Reasoning and Acting in Language Models Yao et al. 2023
- PAL: Program-aided Language Models Gao et al. 2022
- Mind2Web: Towards a Generalist Agent for the Web Deng et al. 2023
- WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents Yao et al. 2023
- WebArena: A Realistic Web Environment for Building Autonomous Agents Zhou et al. 2023
- MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge Fan et al. 2022
- Training language models to follow instructions with human feedback Ouyang et al. 2022
- Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents Song et al. 2024
- Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization Yao et al. 2023
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist