
Tóm tắt: Bài viết này sẽ giới thiệu DataGemma, một mô hình mở được Google phát triển để giảm thiểu ảo giác (hallucinations) trong các mô hình ngôn ngữ lớn (LLMs). DataGemma kết nối LLMs với kho dữ liệu khổng lồ Data Commons thông qua hai kỹ thuật chính là RIG (Retrieval Interleaved Generation) và RAG (Retrieval-Augmented Generation). Bài viết sẽ phân tích chi tiết các kỹ thuật này, cách chúng hoạt động và những kết quả đánh giá của Google.
Table of Contents
Giới thiệu về vấn đề ảo giác trong LLMs
LLMs đang thay đổi cách chúng ta làm việc trong mọi lĩnh vực. Chúng có khả năng xử lý khối lượng văn bản khổng lồ, tóm tắt thông tin, đưa ra ý tưởng sáng tạo và thậm chí viết code. Tuy nhiên, một vấn đề nan giải đối với LLMs là hiện tượng ảo giác (hallucinations) – khi LLM tự tin đưa ra thông tin sai lệch.
Hãy tưởng tượng bạn hỏi LLM về dân số Việt Nam. LLM có thể trả lời là 100 triệu người, nhưng con số này hoàn toàn sai lệch. Điều này xảy ra bởi vì LLM được đào tạo trên lượng dữ liệu khổng lồ, nhưng không phải lúc nào cũng có thể đảm bảo tính chính xác của dữ liệu đó.
Vậy làm sao để giải quyết vấn đề này?
Google giới thiệu DataGemma: Mô hình mở kết nối LLMs với dữ liệu thực tế
Google gần đây đã giới thiệu một giải pháp mới mang tên DataGemma – mô hình mở đầu tiên được thiết kế để kết nối LLMs với Data Commons – kho dữ liệu mã nguồn mở khổng lồ chứa 240 tỉ dữ liệu thống kê công khai. DataGemma sử dụng hai kỹ thuật chính là RIG và RAG để khắc phục vấn đề ảo giác trong LLMs:
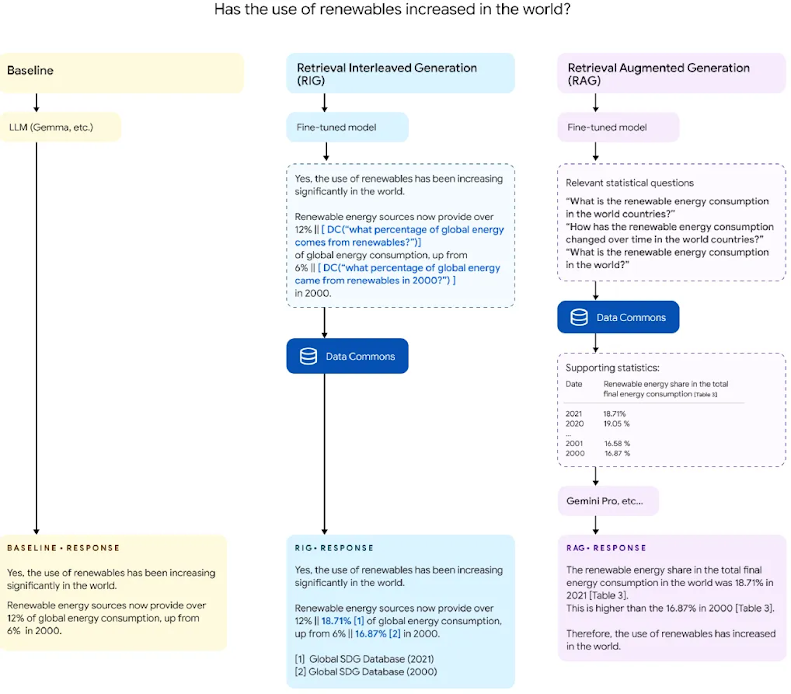
1. RIG (Retrieval-Interleaved Generation): Kiểm tra thực tế bằng dữ liệu
RIG là một kỹ thuật kết hợp LLMs với dữ liệu thực tế từ Data Commons để đảm bảo tính chính xác của thông tin. RIG hoạt động theo các bước sau:
- Fine-tuned LLM: LLM được tinh chỉnh để tạo ra các truy vấn bằng ngôn ngữ tự nhiên (natural language query) liên quan đến prompt đầu vào. Ví dụ, khi nhận được prompt “Dân số Việt Nam là bao nhiêu”, LLM sẽ tạo ra một truy vấn “Dân số của Việt Nam hiện nay là bao nhiêu?”.
- Query Conversion: Truy vấn bằng ngôn ngữ tự nhiên được chuyển đổi thành truy vấn dữ liệu có cấu trúc (structured data query) phù hợp với Data Commons.
- Data Retrieval Engine: Truy vấn được gửi đến Data Commons để lấy dữ liệu tương ứng.
- Result Interleaving: Dữ liệu trả về từ Data Commons được lồng ghép với phản hồi ban đầu từ LLM, giúp cung cấp câu trả lời chính xác hơn.
RIG sử dụng một cách tiếp cận mới:
- LLM được huấn luyện để tạo ra các truy vấn dựa trên ngữ cảnh xung quanh thông tin thống kê.
- Các truy vấn này giúp truy xuất dữ liệu từ Data Commons để kiểm tra thực tế thông tin được LLM đưa ra.
2. RAG (Retrieval-Augmented Generation): Cung cấp thêm ngữ cảnh cho LLMs
RAG cho phép LLMs tích hợp thông tin liên quan từ Data Commons vào quá trình tạo phản hồi, giúp cung cấp câu trả lời đầy đủ và chính xác hơn.
RAG hoạt động theo các bước sau:
- Trích xuất truy vấn ngôn ngữ tự nhiên: Truy vấn của người dùng được chuyển đến một LLM nhỏ đã được tinh chỉnh để tạo ra các natural language query liên quan đến Data Commons.
- Truy xuất tables: Các truy vấn này được chuyển đổi thành truy vấn dữ liệu có cấu trúc và được sử dụng để truy xuất dữ liệu từ Data Commons.
- Prompting: Dữ liệu trả về từ Data Commons được thêm vào prompt ban đầu, giúp LLM tạo ra phản hồi chính xác và đầy đủ hơn.
RAG giúp LLMs:
- Truy cập và sử dụng thông tin liên quan từ Data Commons để làm giàu nội dung phản hồi.
- Giảm thiểu ảo giác bằng cách cung cấp thêm ngữ cảnh và thông tin cho LLM.
Kết quả thử nghiệm và đánh giá
Google đã đánh giá hiệu quả của RIG và RAG thông qua các thử nghiệm thực tế. Kết quả cho thấy:
- RIG: Cải thiện độ chính xác từ 5-17% lên khoảng 58%.
- RAG: Cung cấp độ chính xác cao khi trích dẫn số liệu (99%) nhưng độ chính xác giảm khi đưa ra suy luận dựa trên những số liệu này.
Tuy nhiên, vẫn còn một số hạn chế cần khắc phục:
- Vấn đề về độ chính xác của Data Commons NL interface: Data Commons NL có thể trả về câu trả lời không chính xác do thiếu dữ liệu hoặc lỗi trong quá trình xử lý.
- Irrelevant LLM generated questions: LLM có thể không tạo ra những câu hỏi đủ chính xác để truy xuất thông tin phù hợp từ Data Commons.
Data và code
Bạn có thể truy cập vào repo của DataGemma, embedding weights và Colab Notebooks để thử nghiệm và khám phá mô hình này:
- Repo của DataGemma: https://github.com/datacommonsorg/llm-tools
- Embedding weights: https://huggingface.co/google/datagemma-rig-27b-it và https://www.kaggle.com/models/google/datagemma-rig (RIG); https://huggingface.co/google/datagemma-rag-27b-it và https://www.kaggle.com/models/google/datagemma-rag (RAG)
- Colab Notebooks: https://github.com/datacommonsorg/llm-tools/blob/main/notebooks/data_gemma_rig.ipynb (RIG) và https://github.com/datacommonsorg/llm-tools/blob/main/notebooks/data_gemma_rag.ipynb (RAG)
Bảng so sánh RIG và RAG trong DataGemma
| Tính năng | RIG (Retrieval Interleaved Generation) | RAG (Retrieval-Augmented Generation) |
| Mục tiêu chính | Kiểm tra thực tế thông tin được LLM đưa ra bằng dữ liệu từ Data Commons | Cung cấp thêm ngữ cảnh và thông tin cho LLM từ Data Commons |
| Cách thức hoạt động | LLM được tinh chỉnh để tạo ra các truy vấn dựa trên ngữ cảnh, sau đó truy xuất dữ liệu từ Data Commons để kiểm tra | LLM được cung cấp dữ liệu từ Data Commons trước khi tạo phản hồi |
| Bước chính | Fine-tuning LLM, Query Conversion, Data Retrieval, Result Interleaving | Trích xuất truy vấn, Truy xuất tables, Prompting |
| Kết quả thử nghiệm | Cải thiện độ chính xác từ 5-17% lên khoảng 58% | Độ chính xác cao khi trích dẫn số liệu (99%), nhưng giảm khi đưa ra suy luận |
| Hạn chế | Vấn đề về độ chính xác của Data Commons NL interface, LLM không tạo ra các truy vấn đủ chính xác |
| Kỹ thuật | Mô tả | Ưu điểm | Nhược điểm |
| RIG (Retrieval Interleaved Generation) | Kết hợp LLM với dữ liệu thực tế từ Data Commons để kiểm tra độ chính xác của thông tin. | Cải thiện độ chính xác của LLM bằng cách so sánh thông tin với dữ liệu thực tế. | Phụ thuộc vào độ chính xác của Data Commons và khả năng tạo truy vấn chính xác của LLM. |
| RAG (Retrieval-Augmented Generation) | Cung cấp thêm ngữ cảnh và thông tin từ Data Commons cho LLM để tạo ra phản hồi đầy đủ hơn. | Giúp LLM hiểu rõ hơn ngữ cảnh và tạo ra phản hồi chính xác hơn. | Cần cải thiện khả năng xử lý và kết hợp thông tin từ Data Commons vào phản hồi. |
Lưu ý: Bảng này chỉ cung cấp một cái nhìn tổng quan về hai kỹ thuật RIG và RAG trong DataGemma. Để hiểu rõ hơn về từng kỹ thuật, bạn cần đọc thêm thông tin chi tiết trong bài viết.
Bảng phân tích các bước chính của RIG và RAG
| Bước | RIG (Retrieval Interleaved Generation) | RAG (Retrieval-Augmented Generation) |
| 1. Truy vấn | LLM tạo truy vấn ngôn ngữ tự nhiên dựa trên ngữ cảnh prompt. | Truy vấn của người dùng được chuyển đến một LLM nhỏ đã được tinh chỉnh để tạo ra truy vấn ngôn ngữ tự nhiên phù hợp với Data Commons. |
| 2. Chuyển đổi truy vấn | Truy vấn ngôn ngữ tự nhiên được chuyển đổi thành truy vấn dữ liệu có cấu trúc phù hợp với Data Commons. | Truy vấn ngôn ngữ tự nhiên được chuyển đổi thành truy vấn dữ liệu có cấu trúc phù hợp với Data Commons. |
| 3. Truy xuất dữ liệu | Truy vấn được gửi đến Data Commons để lấy dữ liệu tương ứng. | Truy vấn được gửi đến Data Commons để lấy dữ liệu tương ứng. |
| 4. Xử lý dữ liệu | Dữ liệu trả về được lồng ghép với phản hồi ban đầu từ LLM để cung cấp câu trả lời chính xác hơn. | Dữ liệu trả về được thêm vào prompt ban đầu để cung cấp thêm ngữ cảnh cho LLM. |
| 5. Tạo phản hồi | LLM dựa vào dữ liệu đã được lồng ghép để tạo ra phản hồi cuối cùng. | LLM dựa vào prompt đã được bổ sung dữ liệu để tạo ra phản hồi cuối cùng. |
Nhận xét về DataGemma
DataGemma là một bước tiến đáng chú ý trong việc giải quyết vấn đề ảo giác trong LLMs. Việc kết nối LLMs với kho dữ liệu khổng lồ Data Commons thông qua RIG và RAG đã mang lại những cải thiện rõ rệt về độ chính xác và khả năng lập luận của LLMs.
Tuy nhiên, DataGemma vẫn cần được phát triển thêm để khắc phục các hạn chế:
- Cải thiện độ chính xác của Data Commons NL interface: Google cần tiếp tục nâng cấp Data Commons để đảm bảo độ chính xác và đầy đủ của dữ liệu.
- Tăng cường khả năng tạo ra các truy vấn chính xác: LLMs cần được huấn luyện tốt hơn để tạo ra những truy vấn phù hợp với Data Commons.
Có thể thấy rằng, DataGemma là một giải pháp đầy tiềm năng cho tương lai của LLMs. Với những cải tiến liên tục, DataGemma sẽ giúp LLMs cung cấp thông tin chính xác hơn, đáng tin cậy hơn và hữu ích hơn trong mọi lĩnh vực.
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist