
Bạn muốn thử sức với học máy nhưng chưa biết bắt đầu từ đâu? Đừng lo, bài viết này sẽ cung cấp cho bạn cái nhìn tổng quan về các công cụ và kỹ thuật quan trọng để thực hiện một dự án học máy thành công.
Có thể thấy rằng, học máy là một lĩnh vực đang phát triển mạnh mẽ, mang lại nhiều lợi ích cho nhiều ngành nghề khác nhau. Từ dự đoán giá cổ phiếu, phát hiện gian lận, đến phân loại hình ảnh và dịch thuật tự động, học máy đang thay đổi cách chúng ta làm việc và tương tác với thế giới.
Nhưng để tận dụng được sức mạnh của học máy, bạn cần phải nắm vững các công cụ và kỹ thuật phù hợp. Hãy cùng khám phá những thành phần cốt lõi để thực hiện một dự án học máy, qua bài viết bên dưới nhé!
Table of Contents
Công cụ cần thiết
- Python: Đây là một trong những ngôn ngữ lập trình phổ biến nhất dành cho học máy, Python cung cấp các thư viện như Scikit-Learn, TensorFlow và Keras. Những thư viện này hỗ trợ trong việc xây dựng, huấn luyện và kiểm tra mô hình.
- Ví dụ: Scikit-Learn giúp xây dựng các mô hình hồi quy tuyến tính, phân loại, TensorFlow hỗ trợ mạng nơ-ron sâu, Keras giúp đơn giản hóa việc xây dựng mạng nơ-ron.
- Jupyter Notebook: Đây là một môi trường tương tác để viết mã, trực quan hóa dữ liệu và tài liệu hóa công việc của bạn trong thời gian thực.
- Ví dụ: Bạn có thể trực tiếp viết mã Python, hiển thị biểu đồ, chèn chú thích giải thích ngay trong Jupyter Notebook, giúp quá trình phát triển mô hình trở nên trực quan và dễ dàng chia sẻ với người khác. Jupyter Notebook cũng hỗ trợ nhiều ngôn ngữ lập trình khác như R, Julia, giúp bạn linh hoạt lựa chọn công cụ phù hợp với nhu cầu.
- Google Colab: Dịch vụ này cung cấp hỗ trợ GPU miễn phí, cho phép bạn chạy các mô hình phức tạp mà không cần phần cứng đắt tiền.
- Ví dụ: Google Colab rất hữu ích cho việc huấn luyện các mạng nơ-ron sâu đòi hỏi nhiều tài nguyên tính toán. Google Colab cũng hỗ trợ chia sẻ mã và kết quả với cộng đồng, giúp bạn học hỏi từ những người khác và đóng góp vào cộng đồng học máy.
- Pandas và NumPy: Đây là hai thư viện cần thiết cho thao tác dữ liệu và tính toán số học, giúp bạn dễ dàng làm sạch và xử lý dữ liệu trước khi đưa vào mô hình.
- Ví dụ: Pandas giúp bạn đọc, viết, xử lý dữ liệu trong các bảng dữ liệu, NumPy cung cấp các phép toán ma trận, vector hiệu quả cho việc tính toán trong học máy. Pandas và NumPy là những công cụ mạnh mẽ giúp bạn biến đổi dữ liệu thô thành dạng phù hợp để đưa vào mô hình học máy.
- Visual Studio Code: Một công cụ mã hóa đa năng với nhiều tiện ích mở rộng hỗ trợ học máy, giúp bạn viết mã, gỡ lỗi và quản lý dự án hiệu quả.
- Ví dụ: Visual Studio Code cung cấp các tiện ích mở rộng hỗ trợ Python, TensorFlow, Keras, giúp bạn viết mã nhanh chóng và hiệu quả hơn. Visual Studio Code cũng hỗ trợ tích hợp với Git, giúp bạn quản lý mã nguồn và hợp tác với các thành viên trong nhóm.
So sánh Jupyter và Google Colab:
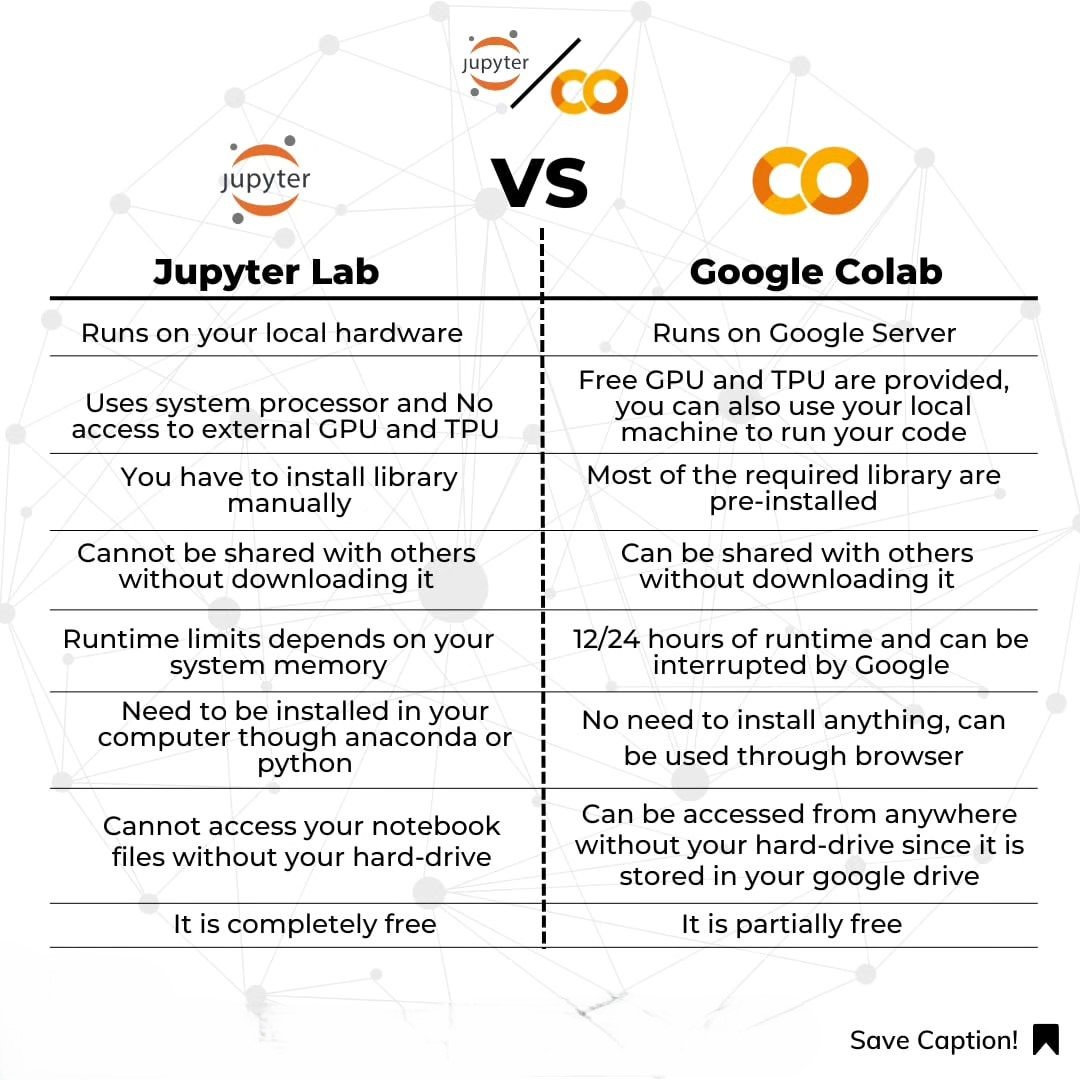
| Jupyter Lab | Google Colab |
| Chạy trên phần cứng cục bộ của bạn | Chạy trên máy chủ của Google |
| Sử dụng bộ xử lý hệ thống và không có quyền truy cập vào GPU và TPU bên ngoài | Cung cấp miễn phí GPU và TPU, bạn cũng có thể sử dụng máy cục bộ để chạy mã của mình |
| Bạn phải cài đặt thư viện thủ công | Hầu hết các thư viện cần thiết được cài đặt sẵn |
| Không thể chia sẻ với người khác nếu không tải xuống | Có thể chia sẻ với người khác mà không cần tải xuống |
| Giới hạn thời gian chạy phụ thuộc vào bộ nhớ hệ thống của bạn | 12/24 giờ thời gian chạy và có thể bị gián đoạn bởi Google |
| Cần phải cài đặt trên máy tính của bạn thông qua Anaconda hoặc Python | Không cần cài đặt gì, có thể sử dụng thông qua trình duyệt |
| Không thể truy cập vào tệp ghi chú của bạn nếu không có ổ cứng | Có thể truy cập từ mọi nơi mà không cần ổ cứng vì được lưu trữ trong Google Drive của bạn |
| Hoàn toàn miễn phí | Miễn phí một phần |
Kỹ thuật quan trọng
- Xử lý dữ liệu: Làm sạch dữ liệu (xử lý giá trị thiếu, ngoại lệ) và chuẩn hóa dữ liệu là điều cần thiết để đảm bảo mô hình hoạt động tốt.
- Ví dụ: Xử lý giá trị thiếu bằng cách thay thế bằng giá trị trung bình, loại bỏ ngoại lệ bằng cách sử dụng các phương pháp thống kê giúp cải thiện độ chính xác của mô hình. Các kỹ thuật xử lý dữ liệu khác như mã hóa one-hot, chuẩn hóa dữ liệu (min-max scaling, standardization) cũng đóng vai trò quan trọng trong việc cải thiện hiệu suất của mô hình.
- Chọn lọc đặc trưng: Giảm số lượng biến đầu vào để tránh overfitting và cải thiện độ chính xác.
- Ví dụ: Các phương pháp chọn lọc đặc trưng như phương pháp tương quan, phương pháp chọn lọc dựa trên độ quan trọng của đặc trưng giúp giảm số lượng đặc trưng không cần thiết, nâng cao hiệu suất của mô hình. Ngoài ra, bạn có thể sử dụng kỹ thuật giảm chiều (dimensionality reduction) như PCA (Principal Component Analysis) để giảm số lượng đặc trưng và tối ưu hóa mô hình.
- Chọn mô hình: Chọn các thuật toán phù hợp dựa trên loại dữ liệu và mục tiêu dự án, ví dụ như cây quyết định, rừng ngẫu nhiên hoặc mạng nơ-ron.
- Ví dụ: Nếu bạn muốn dự đoán biến liên tục, bạn có thể sử dụng hồi quy tuyến tính. Nếu bạn muốn phân loại các đối tượng, bạn có thể sử dụng cây quyết định hoặc mạng nơ-ron. Ngoài ra, các mô hình học sâu (deep learning) như Convolutional Neural Networks (CNN) cho xử lý hình ảnh, Recurrent Neural Networks (RNN) cho xử lý ngôn ngữ tự nhiên cũng là những lựa chọn phổ biến trong các dự án học máy hiện nay.
- Điều chỉnh siêu tham số: Điều chỉnh các tham số để tối ưu hóa hiệu suất mô hình bằng cách sử dụng các kỹ thuật như Grid Search hoặc Random Search.
- Ví dụ: Thay đổi các tham số của thuật toán như độ sâu của cây quyết định, số lượng cây trong rừng ngẫu nhiên để tìm ra bộ tham số tốt nhất cho dữ liệu của bạn. Ngoài Grid Search và Random Search, bạn có thể sử dụng các kỹ thuật tối ưu hóa tự động như Bayesian Optimization, Evolutionary Optimization để tìm kiếm siêu tham số hiệu quả hơn.
- Kiểm tra chéo: Chia bộ dữ liệu để kiểm tra hiệu suất của mô hình nhằm đảm bảo khả năng tổng quát hóa cho dữ liệu mới, chưa từng gặp trước đó.
- Ví dụ: Kiểm tra chéo k-fold giúp đánh giá hiệu suất của mô hình trên các tập dữ liệu khác nhau, đảm bảo mô hình hoạt động ổn định và chính xác. Ngoài k-fold, bạn có thể sử dụng các kỹ thuật kiểm tra chéo khác như leave-one-out cross-validation, stratified cross-validation để phù hợp với đặc thù của dữ liệu.
Nhận xét
Để thành công trong việc ứng dụng học máy, việc nắm vững các công cụ và kỹ thuật phù hợp là điều vô cùng cần thiết. Từ việc lựa chọn ngôn ngữ lập trình phù hợp, sử dụng các thư viện hỗ trợ, đến kỹ thuật xử lý dữ liệu, chọn lọc đặc trưng, và điều chỉnh siêu tham số, mỗi bước đều đóng vai trò quan trọng trong việc tạo ra mô hình học máy hiệu quả. Không chỉ có kiến thức chuyên môn, sự kiên trì, khả năng học hỏi và tinh thần cộng đồng cũng là những yếu tố góp phần vào sự thành công của bạn trong hành trình chinh phục thế giới học máy.
Kết luận
Những công cụ và kỹ thuật này có thể giúp bạn tối ưu hóa quy trình học máy, đảm bảo kết quả chính xác và đáng tin cậy. Mọi người hãy nhớ rằng, sự thành công của dự án phụ thuộc vào việc lựa chọn và áp dụng hiệu quả các công cụ và kỹ thuật phù hợp. Theo Click Digital, học máy là một lĩnh vực rộng lớn và đầy tiềm năng, nhưng đòi hỏi sự kiên trì và nỗ lực không ngừng để đạt được kết quả tốt nhất.
Bên cạnh việc trang bị kiến thức, bạn cũng nên tham gia vào cộng đồng học máy để học hỏi từ những người khác, chia sẻ kinh nghiệm và cùng nhau phát triển lĩnh vực này.
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist