
Summary: This article introduces DataGemma, an open-source model developed by Google to mitigate hallucinations in large language models (LLMs). DataGemma connects LLMs to the massive Data Commons repository using two primary techniques: RIG (Retrieval Interleaved Generation) and RAG (Retrieval-Augmented Generation). We will delve into these techniques, how they operate, and the evaluation results from Google.
Table of Contents
Understanding Hallucinations in LLMs
LLMs are transforming the way we work across various fields. They can process vast amounts of text, generate summaries, offer creative ideas, and even write code. However, a significant challenge facing LLMs is the phenomenon of hallucinations – when an LLM confidently produces incorrect information.
Imagine asking an LLM about the population of Vietnam. It might respond with 100 million, which is completely inaccurate. This happens because LLMs are trained on massive datasets, but the accuracy of this data isn’t always guaranteed.
So, how can we address this issue?
Google Introduces DataGemma: Connecting LLMs to Real-World Data
Google recently unveiled a new solution called DataGemma – the first open-source model designed to link LLMs with Data Commons, a vast repository of 240 billion publicly available statistical data. DataGemma employs two key techniques: RIG and RAG to overcome hallucinations in LLMs:
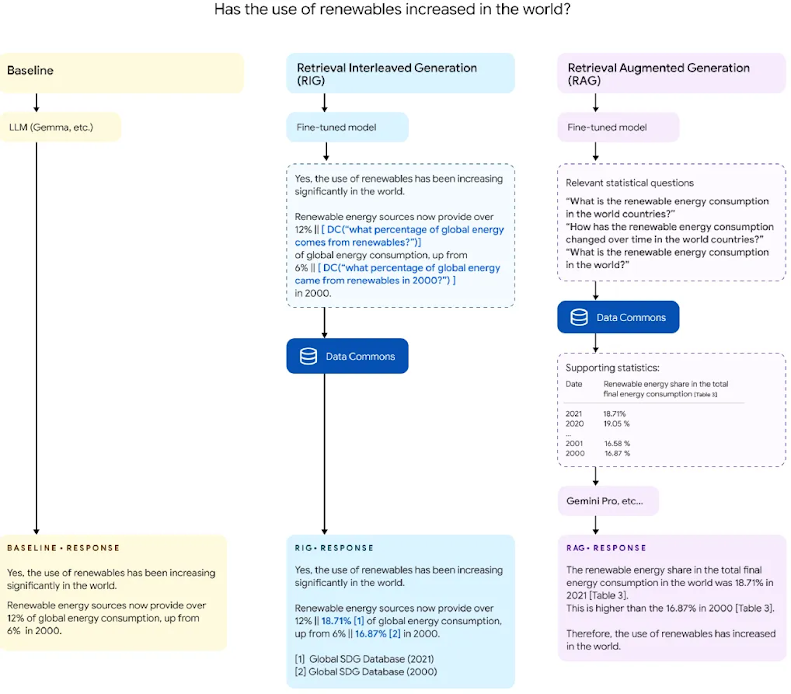
1. RIG (Retrieval Interleaved Generation): Fact-Checking with Data
RIG is a technique that combines LLMs with real-world data from Data Commons to ensure information accuracy. RIG operates in the following steps:
Fine-tuned LLM: The LLM is fine-tuned to generate natural language queries related to the input prompt. For example, when receiving the prompt “What is the population of Vietnam?”, the LLM will generate a query like “What is the current population of Vietnam?”.
Query Conversion: The natural language query is converted into a structured data query suitable for Data Commons.
Data Retrieval Engine: The query is sent to Data Commons to retrieve relevant data.
Result Interleaving: The data retrieved from Data Commons is interwoven with the initial LLM response, providing a more accurate answer.
RIG utilizes a novel approach:
- LLMs are trained to generate queries based on the context surrounding the statistical information.
- These queries enable data retrieval from Data Commons to fact-check the information provided by the LLM.
2. RAG (Retrieval-Augmented Generation): Providing Additional Context for LLMs
RAG allows LLMs to integrate relevant information from Data Commons during the response generation process, delivering more comprehensive and accurate answers.
RAG functions in these steps:
Extracting Natural Language Queries: User queries are passed to a smaller, fine-tuned LLM to generate natural language queries relevant to Data Commons.
Retrieving Tables: These queries are converted to structured data queries and used to retrieve data from Data Commons.
Prompting: The retrieved data from Data Commons is added to the initial prompt, aiding the LLM in generating accurate and comprehensive responses.
RAG empowers LLMs to:
- Access and utilize relevant information from Data Commons to enrich response content.
- Mitigate hallucinations by providing additional context and information to the LLM.
Experimental Results and Evaluation
Google has assessed the effectiveness of RIG and RAG through real-world experiments. The results indicate:
RIG: Improved accuracy from 5-17% to around 58%.
RAG: Achieved high accuracy in quoting numerical data (99%) but saw accuracy decline when making inferences based on these figures.
However, there are some limitations that need to be addressed:
Issues with Data Commons NL Interface Accuracy: Data Commons NL might return inaccurate responses due to data gaps or processing errors.
Irrelevant LLM Generated Questions: LLMs might not generate sufficiently accurate questions to retrieve appropriate information from Data Commons.
Data and Code
You can access DataGemma’s repository, embedding weights, and Colab Notebooks to experiment and explore this model:
DataGemma Repository: https://github.com/datacommonsorg/llm-tools
Embedding Weights: https://huggingface.co/google/datagemma-rig-27b-it and https://www.kaggle.com/models/google/datagemma-rig (RIG); https://huggingface.co/google/datagemma-rag-27b-it and https://www.kaggle.com/models/google/datagemma-rag (RAG)
Colab Notebooks: https://github.com/datacommonsorg/llm-tools/blob/main/notebooks/data_gemma_rig.ipynb (RIG) and https://github.com/datacommonsorg/llm-tools/blob/main/notebooks/data_gemma_rag.ipynb (RAG)
Comparison Table of RIG and RAG in DataGemma
| Feature | RIG (Retrieval Interleaved Generation) | RAG (Retrieval-Augmented Generation) |
| Main Goal | Fact-checks information provided by LLM using data from Data Commons | Provides additional context and information to LLM from Data Commons |
| How it works | LLM is fine-tuned to generate queries based on context, then retrieves data from Data Commons to verify | LLM is provided with data from Data Commons before generating a response |
| Key Steps | Fine-tuning LLM, Query Conversion, Data Retrieval, Result Interleaving | Extracting queries, Retrieving tables, Prompting |
| Evaluation Results | Improved accuracy from 5-17% to around 58% | High accuracy when quoting numerical data (99%), but accuracy decreases when making inferences |
| Limitations | Issues with accuracy of Data Commons NL interface, LLM does not generate sufficiently accurate queries |
Breakdown of Key Steps for RIG and RAG
| Step | RIG (Retrieval Interleaved Generation) | RAG (Retrieval-Augmented Generation) |
| 1. Query | LLM generates a natural language query based on the prompt context. | User query is passed to a smaller, fine-tuned LLM to generate a natural language query suitable for Data Commons. |
| 2. Query Conversion | The natural language query is converted into a structured data query suitable for Data Commons. | The natural language query is converted into a structured data query suitable for Data Commons. |
| 3. Data Retrieval | The query is sent to Data Commons to retrieve relevant data. | The query is sent to Data Commons to retrieve relevant data. |
| 4. Data Processing | Retrieved data is interwoven with the initial LLM response to provide a more accurate answer. | Retrieved data is added to the initial prompt to provide additional context to the LLM. |
| 5. Response Generation | LLM relies on the interwoven data to generate the final response. | LLM relies on the data-enriched prompt to generate the final response. |
Comparison of Advantages and Disadvantages of RIG and RAG
| Technique | Description | Advantages | Disadvantages |
| RIG (Retrieval Interleaved Generation) | Combines LLM with real-world data from Data Commons to verify the accuracy of information. | * Improves LLM accuracy by comparing information with real-world data. * Helps LLMs avoid generating incorrect information (hallucinations). | * Depends on the accuracy of Data Commons and the LLM’s ability to generate accurate queries. * May struggle to handle complex or unavailable information in Data Commons. |
| RAG (Retrieval-Augmented Generation) | Provides additional context and information from Data Commons to LLM to generate more comprehensive responses. | * Helps LLMs understand context better and generate more accurate responses. * Provides supplementary information and enriches the content of LLM responses. | * Requires improved ability to process and integrate information from Data Commons into responses. * May lead to verbose or irrelevant responses if added information is not appropriate. |
Conclusion
DataGemma represents a significant advancement in tackling hallucinations within LLMs. Integrating LLMs with the vast Data Commons repository through RIG and RAG has resulted in notable improvements in LLM accuracy and reasoning capabilities.
However, DataGemma still requires further development to overcome its limitations:
Improving Data Commons NL Interface Accuracy: Google needs to continue enhancing Data Commons to ensure data accuracy and completeness.
Enhancing the Ability to Generate Accurate Queries: LLMs need to be trained more effectively to generate queries that align with Data Commons.
It is evident that DataGemma is a promising solution for the future of LLMs. With ongoing improvements, DataGemma will empower LLMs to deliver more accurate, reliable, and helpful information across diverse domains.