
Chào mọi người, hãy chuẩn bị cho một cuộc tiến hóa đáng chú ý trong lĩnh vực trí tuệ nhân tạo. Phiên bản GPT-4V, sản phẩm của nhóm nghiên cứu hàng đầu tại OpenAI, đã chính thức ra mắt và đánh dấu một bước tiến đột phá mới trong khả năng tạo ra và tương tác với nội dung được tạo bởi máy tính. GPT-4V không chỉ là một bản cập nhật, mà nó là một sự nâng cấp đáng kể so với những gì chúng tôi đã thấy trong quá khứ, và nó hứa hẹn định hình một tương lai tươi sáng với trí tuệ nhân tạo. Hãy cùng khám phá những tính năng và tiềm năng phiên bản GPT-4V mang lại trong bài viết dưới đây.
Vào ngày 25 tháng 9 năm 2023, OpenAI đã công bố triển khai hai tính năng mới giúp mở rộng cách mọi người có thể tương tác với mẫu GPT-4: khả năng đặt câu hỏi về hình ảnh và sử dụng giọng nói làm đầu vào cho truy vấn.
Table of Contents
GPT-4V là gì? Khác gì ChatGPT 4?
GPT-4V là GPT-4 tích hợp Vision (tầm nhìn), cho phép người dùng hướng dẫn GPT-4 phân tích đầu vào hình ảnh do người dùng cung cấp và là khả năng mới nhất mà chúng tôi đang cung cấp rộng rãi.
Việc kết hợp các phương thức bổ sung (như đầu vào hình ảnh) vào các mô hình ngôn ngữ lớn (LLM) được một số người coi là biên giới quan trọng trong nghiên cứu và phát triển trí tuệ nhân tạo. LLM đa phương thức (Multimodal LLM) cung cấp khả năng mở rộng tác động của các hệ thống chỉ có ngôn ngữ với giao diện và khả năng mới, cho phép chúng giải quyết các nhiệm vụ mới và cung cấp trải nghiệm mới cho người dùng.
Cách GPT-4V được đào tạo?
Tương tự như GPT-4, quá trình đào tạo GPT-4V đã hoàn thành vào năm 2022 và chúng tôi bắt đầu cung cấp quyền truy cập sớm vào hệ thống vào tháng 3 năm 2023. Vì GPT-4 là công nghệ đằng sau khả năng trực quan của GPT-4V nên quy trình đào tạo của nó cũng giống như vậy. Mô hình được đào tạo trước lần đầu tiên được đào tạo để dự đoán từ tiếp theo trong tài liệu, sử dụng tập dữ liệu lớn về dữ liệu văn bản và hình ảnh từ Internet cũng như các nguồn dữ liệu được cấp phép. Sau đó, nó được tinh chỉnh với dữ liệu bổ sung, sử dụng thuật toán gọi là học tăng cường từ phản hồi của con người (reinforcement learning from human feedback) (RLHF) để tạo ra kết quả đầu ra hợp lý.
Công dụng của GPT-4V
GPT-4 với Vision có thể phân tích chữ viết tay.
GPT-4V có thể tạo mã cho một trang web bằng cách sử dụng bản vẽ trên giấy.
GPT-4V có thể phân tích meme.
GPT-4 với Vision có thể viết mô tả sản phẩm cho các trang bán hàng và danh sách sản phẩm trên Amazon.
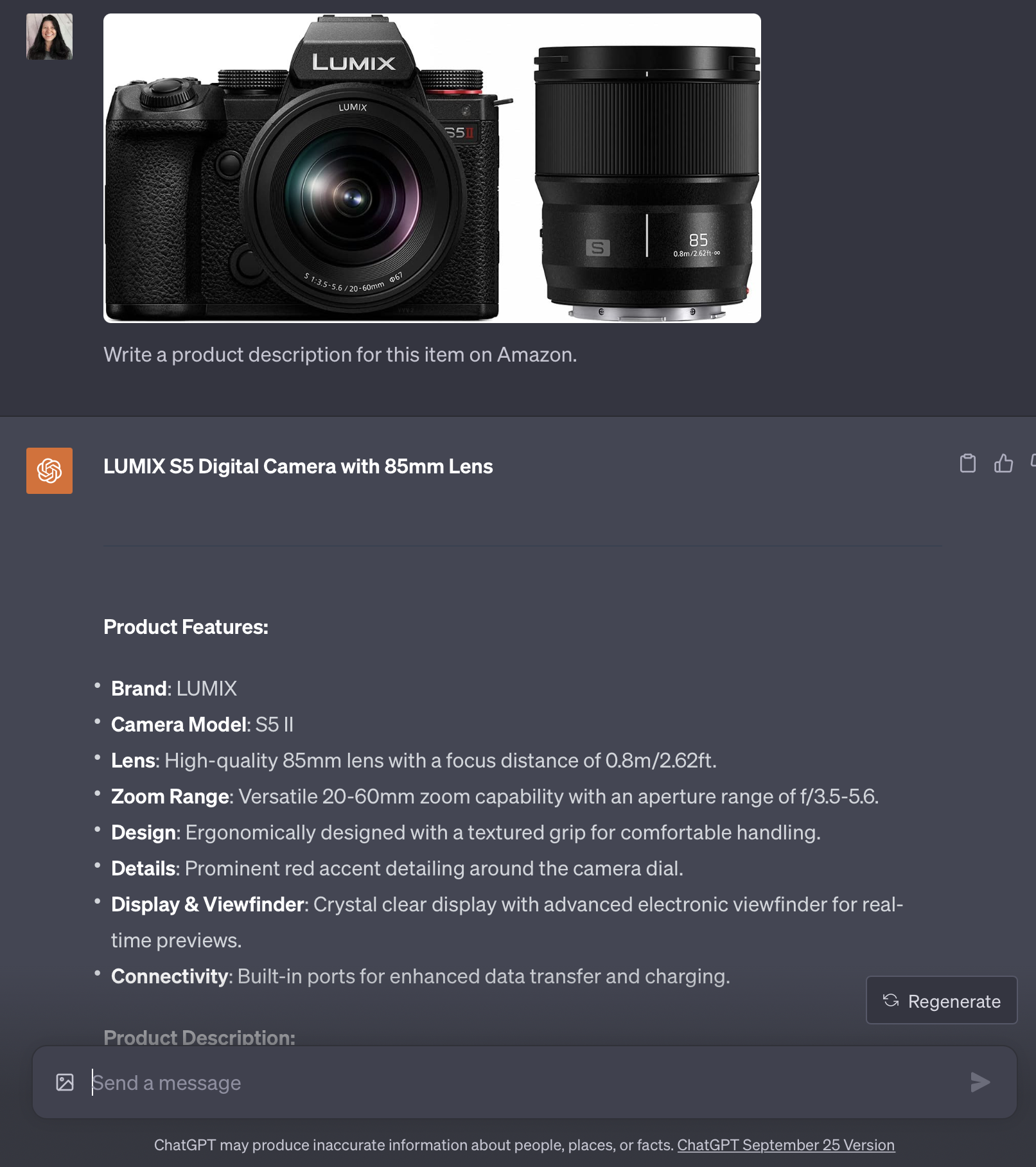
Nó có thể viết chú thích Instagram sáng tạo với các gợi ý hashtag.
Cách để sử dụng Chat GPT-4V
GPT-4V sẽ có sẵn trong cả ứng dụng OpenAI ChatGPT iOS và giao diện web. Bạn phải đăng ký GPT-4 để sử dụng công cụ này.
Trong bài viết này, chúng tôi sẽ chia sẻ những ấn tượng đầu tiên của mình với tính năng nhập hình ảnh GPT-4V. Chúng tôi sẽ thực hiện một loạt thử nghiệm để kiểm tra chức năng của GPT-4V, cho thấy mô hình hoạt động tốt ở đâu và nó gặp khó khăn ở đâu.
Các thử nghiệm thêm cho GPT-4V
Bài kiểm tra số 1: Trả lời câu hỏi bằng hình ảnh
Một trong những thử nghiệm đầu tiên của chúng tôi với GPT-4V là tìm hiểu về meme thị giác máy tính. Chúng tôi chọn thử nghiệm này vì nó cho phép chúng tôi hiểu được bối cảnh và mối quan hệ trong một hình ảnh nhất định ở mức độ nào đó.
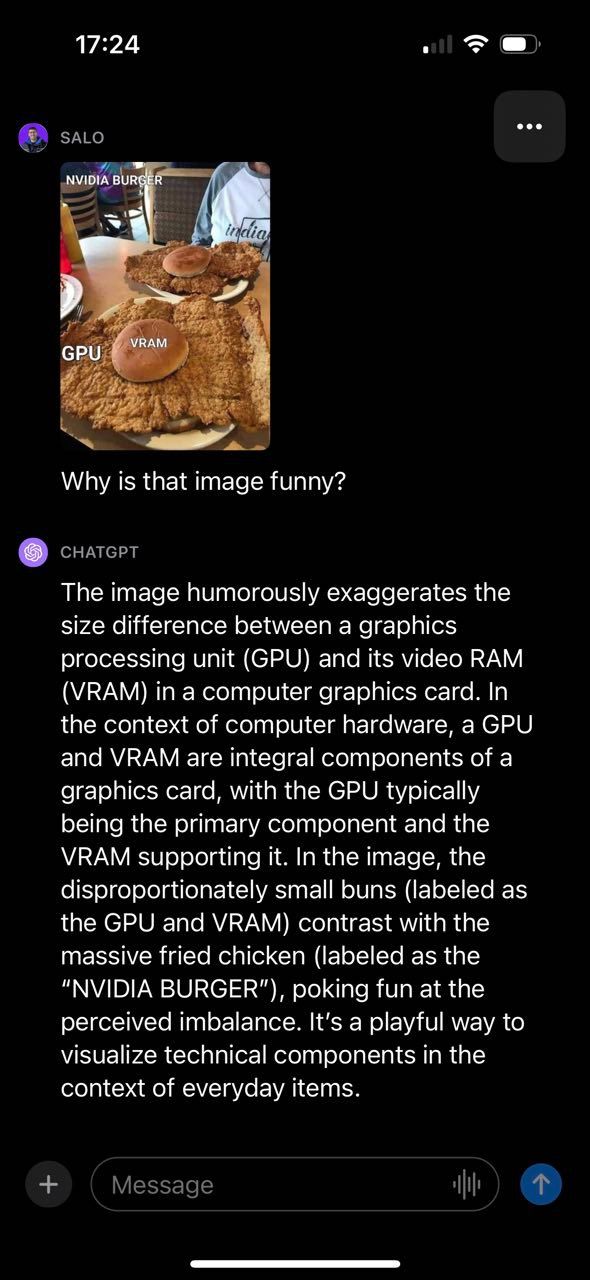
GPT-4V đã có thể mô tả thành công lý do khiến hình ảnh trở nên hài hước, liên quan đến các thành phần khác nhau của hình ảnh và cách chúng kết nối. Đáng chú ý, meme được cung cấp chứa văn bản mà GPT-4V có thể đọc và sử dụng để tạo phản hồi. Như đã nói, GPT-4V đã mắc sai lầm. Người mẫu cho biết món gà rán được dán nhãn “NVIDIA BURGER” thay vì “GPU”.
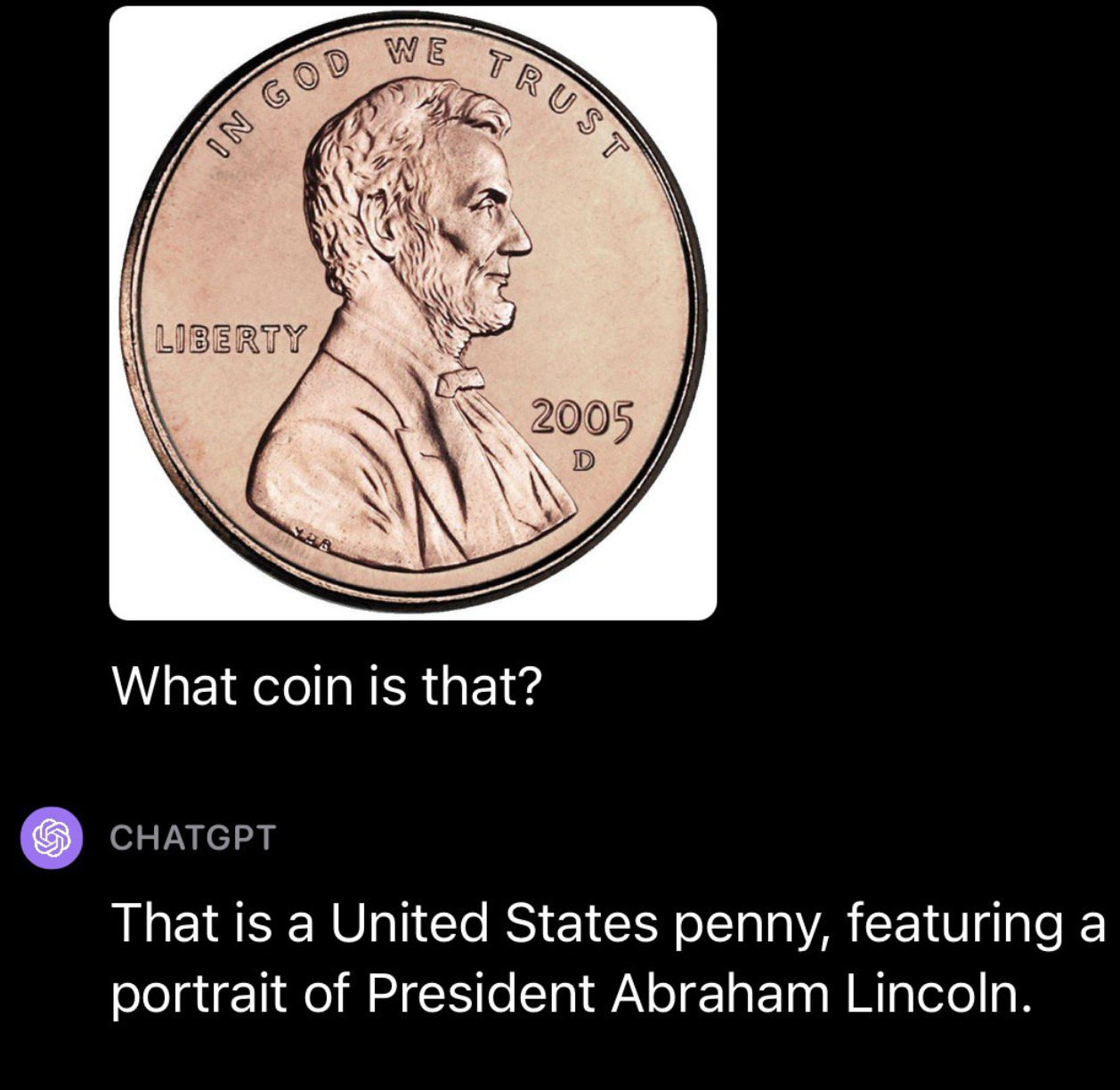
Sau đó, chúng tôi tiếp tục thử nghiệm GPT-4V bằng tiền tệ, thực hiện một số thử nghiệm khác nhau. Đầu tiên, chúng tôi tải lên một bức ảnh về một đồng xu của Hoa Kỳ. GPT-4V đã có thể xác định thành công nguồn gốc và mệnh giá của đồng xu:
Sau đó, chúng tôi tải lên một hình ảnh có nhiều đồng xu và nhắc GPT-4V với dòng chữ: “Tôi có bao nhiêu tiền?”
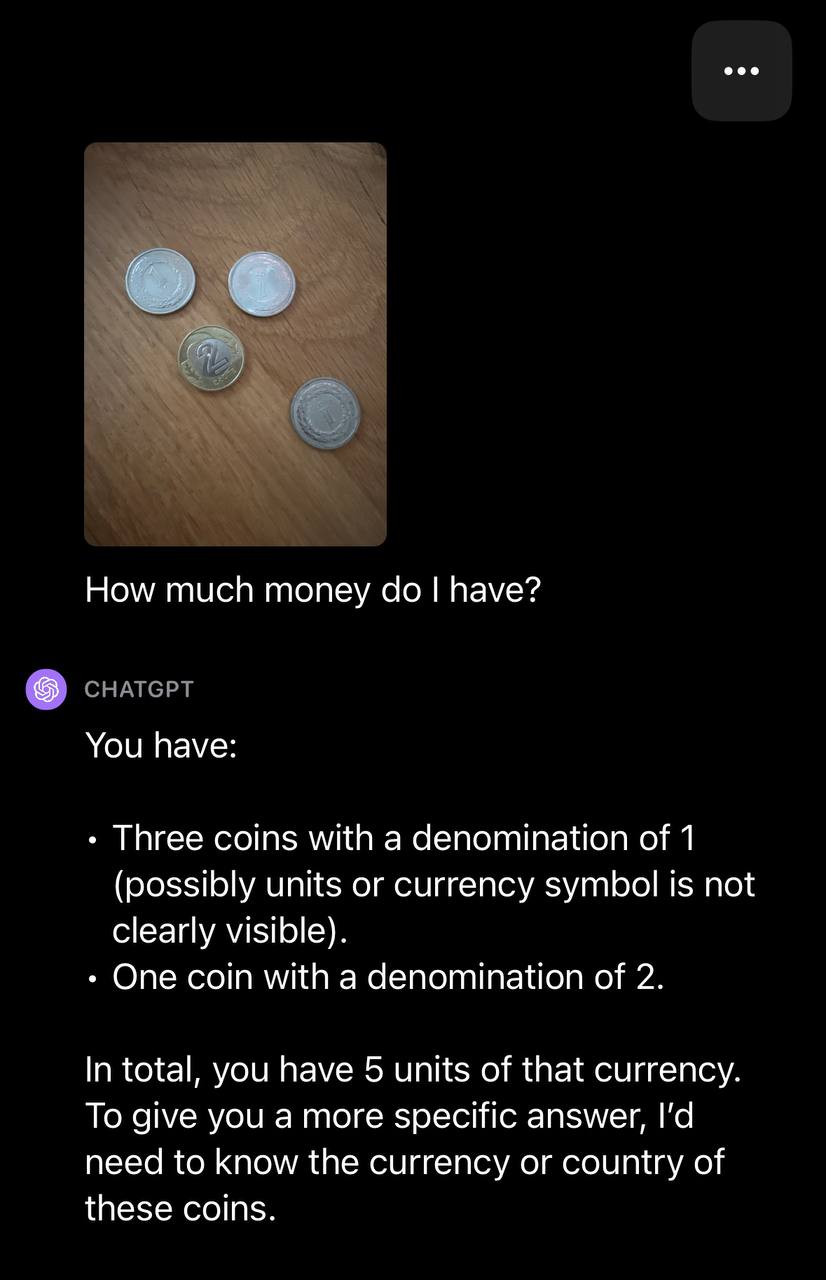
GPT-4V có thể xác định số lượng xu nhưng không xác định được loại tiền tệ. Với câu hỏi tiếp theo, GPT-4V đã xác định thành công loại tiền tệ:

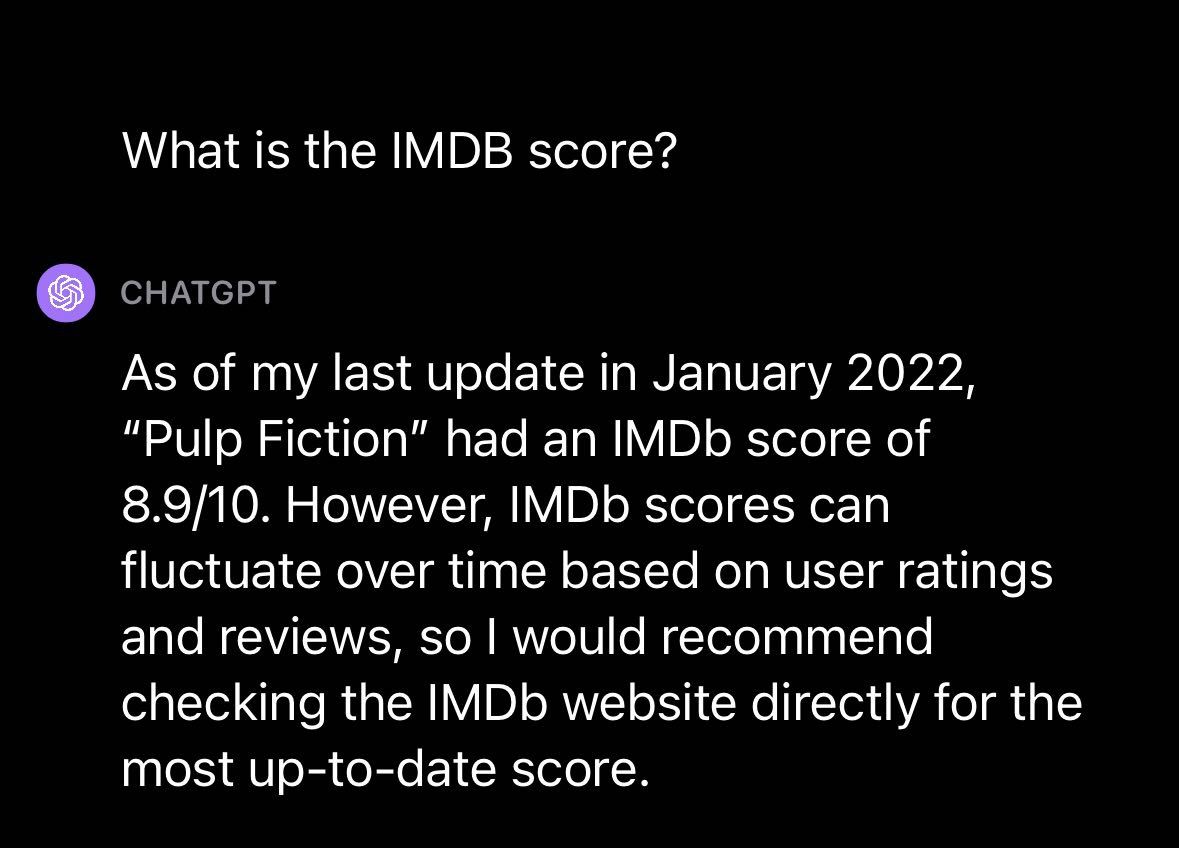
Chuyển sang chủ đề khác, chúng tôi quyết định thử sử dụng GPT-4V với ảnh từ bộ phim nổi tiếng: Pulp Fiction. Chúng tôi muốn biết: liệu GPT-4 có thể trả lời câu hỏi về bộ phim mà không cần cho biết đó là bộ phim gì không?
Chúng tôi đã tải lên một bức ảnh từ Pulp Fiction với lời nhắc “Đây có phải là một bộ phim hay không?”, GPT-4V đã phản hồi bằng mô tả về bộ phim và câu trả lời cho câu hỏi của chúng tôi. GPT-4V cung cấp mô tả cấp cao về phim và bản tóm tắt các thuộc tính liên quan đến phim được coi là tích cực và tiêu cực.
Chúng tôi đã hỏi thêm về điểm IMDB cho bộ phim và GPT-4V đã phản hồi bằng điểm tính đến tháng 1 năm 2022. Điều này cho thấy, giống như các mô hình GPT khác do OpenAI phát hành, sẽ có một giới hạn về kiến thức sau thời điểm đó mô hình không còn cập nhật dữ liệu gần đây nữa. kiến thức.
Sau đó, chúng tôi khám phá khả năng trả lời câu hỏi của GPT-4V bằng cách đặt câu hỏi về một địa điểm. Chúng tôi đã tải lên một bức ảnh về San Francisco với dòng chữ nhắc nhở “Đây là đâu?” GPT-4V đã xác định thành công địa điểm, San Francisco và lưu ý rằng Kim tự tháp Transamerica, trong hình ảnh chúng tôi đã tải lên, là một địa danh đáng chú ý trong thành phố.

Chuyển sang lĩnh vực thực vật, chúng tôi cung cấp cho GPT-4V một bức ảnh về hoa huệ hòa bình và đặt câu hỏi “Cây đó là gì và tôi nên quan tâm đến nó như thế nào?”:
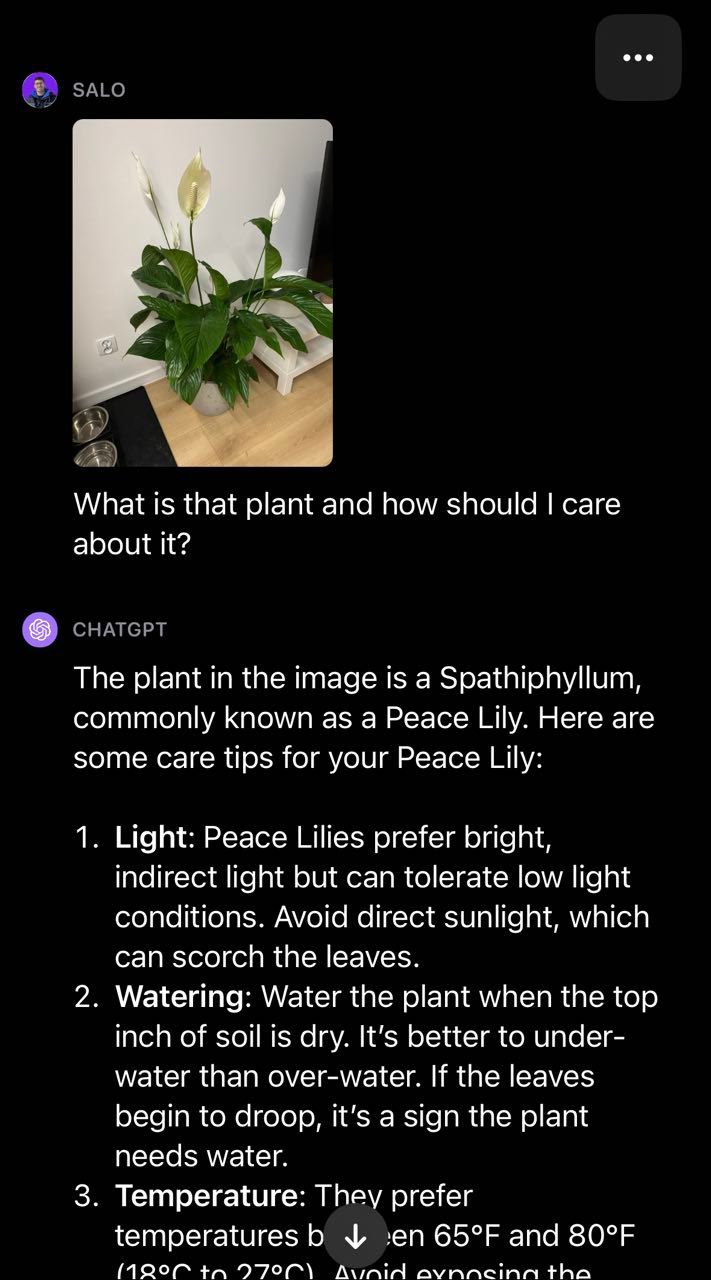
Mô hình đã xác định thành công rằng cây này là hoa huệ hòa bình và đưa ra lời khuyên về cách chăm sóc cây. Điều này minh họa tiện ích của việc kết hợp văn bản và hình ảnh để tạo ra đa phương thức giống như trong GPT-4V. Mô hình trả lại câu trả lời trôi chảy cho câu hỏi của chúng tôi mà không cần phải xây dựng quy trình hai giai đoạn của riêng chúng tôi (tức là phân loại để xác định cây sau đó là GPT-4 để đưa ra lời khuyên chăm sóc cây).
Bài kiểm tra số 2: Nhận dạng ký tự quang học (OCR)
Chúng tôi đã tiến hành hai thử nghiệm để khám phá khả năng OCR của GPT-4V: OCR trên hình ảnh có văn bản trên lốp ô tô và OCR trên ảnh có đoạn văn từ tài liệu kỹ thuật số. Mục đích của chúng tôi là xây dựng sự hiểu biết về cách GPT-4V hoạt động ở OCR trong điều kiện tự nhiên, trong đó văn bản có thể có ít độ tương phản hơn và nằm ở một góc so với các tài liệu kỹ thuật số có văn bản rõ ràng.

GPT-4V không thể xác định chính xác số sê-ri trong hình ảnh lốp xe. Một số con số đúng nhưng có một số lỗi trong kết quả từ mô hình.
Trong quá trình kiểm tra tài liệu, chúng tôi đã trình bày văn bản từ một trang web và yêu cầu GPT-4V đọc văn bản trong hình ảnh. Mô hình đã có thể xác định thành công văn bản trong hình ảnh.
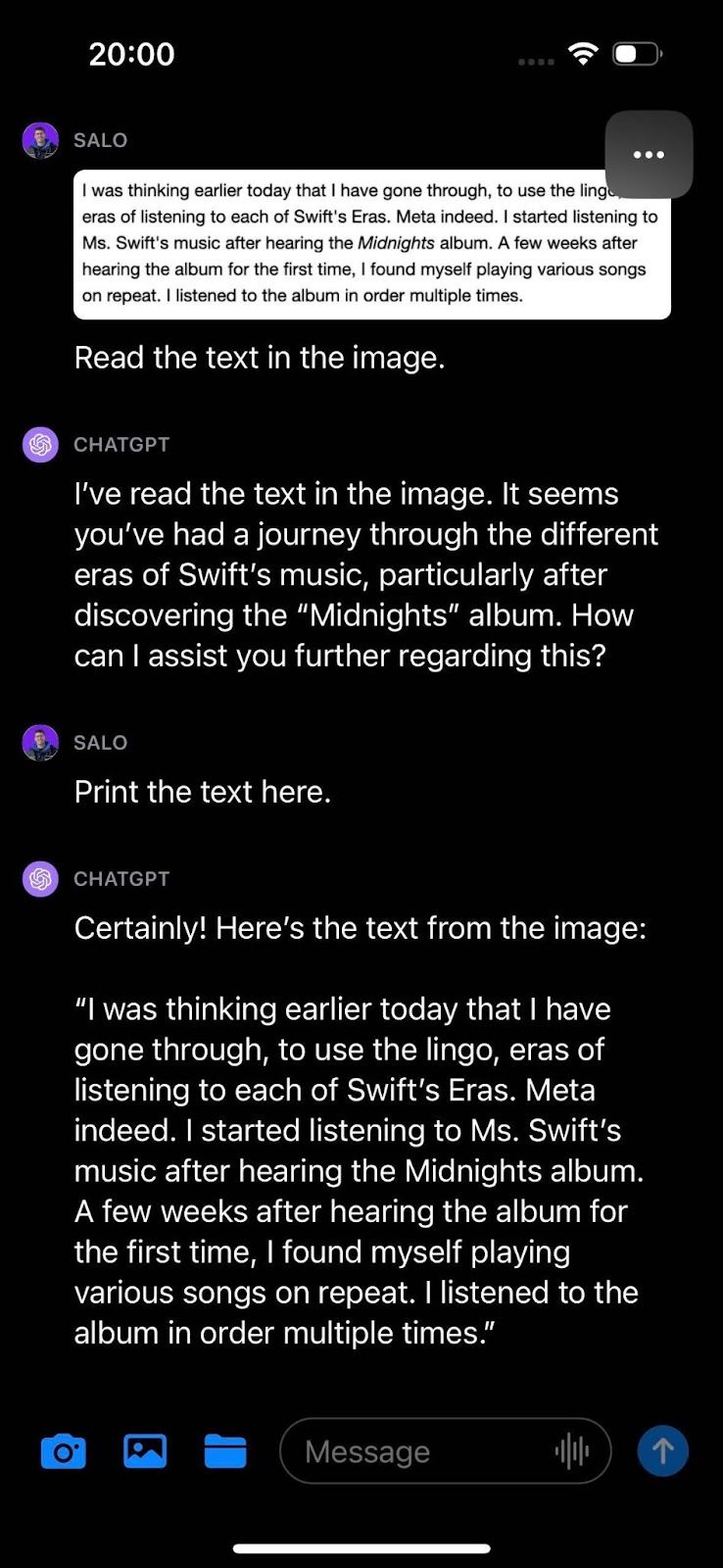
GPT-4V thực hiện xuất sắc công việc dịch các từ trong hình ảnh sang các ký tự riêng lẻ trong văn bản. Thông tin chi tiết hữu ích cho các tác vụ liên quan đến trích xuất văn bản từ tài liệu.
Bài kiểm tra số 3: Toán OCR
Math OCR là một dạng OCR chuyên dụng liên quan cụ thể đến các phương trình toán học. Toán học OCR thường được coi là môn học riêng của nó vì cú pháp của những gì mô hình OCR cần xác định mở rộng đến một phạm vi rộng lớn các ký hiệu.
Chúng tôi đã trình bày GPT-4V một câu hỏi toán học. Câu hỏi toán học này nằm trong ảnh chụp màn hình được lấy từ một tài liệu. Câu hỏi liên quan đến việc tính chiều dài của dây zip khi biết hai góc. Chúng tôi đã trình bày hình ảnh với lời nhắc “Giải quyết nó”.
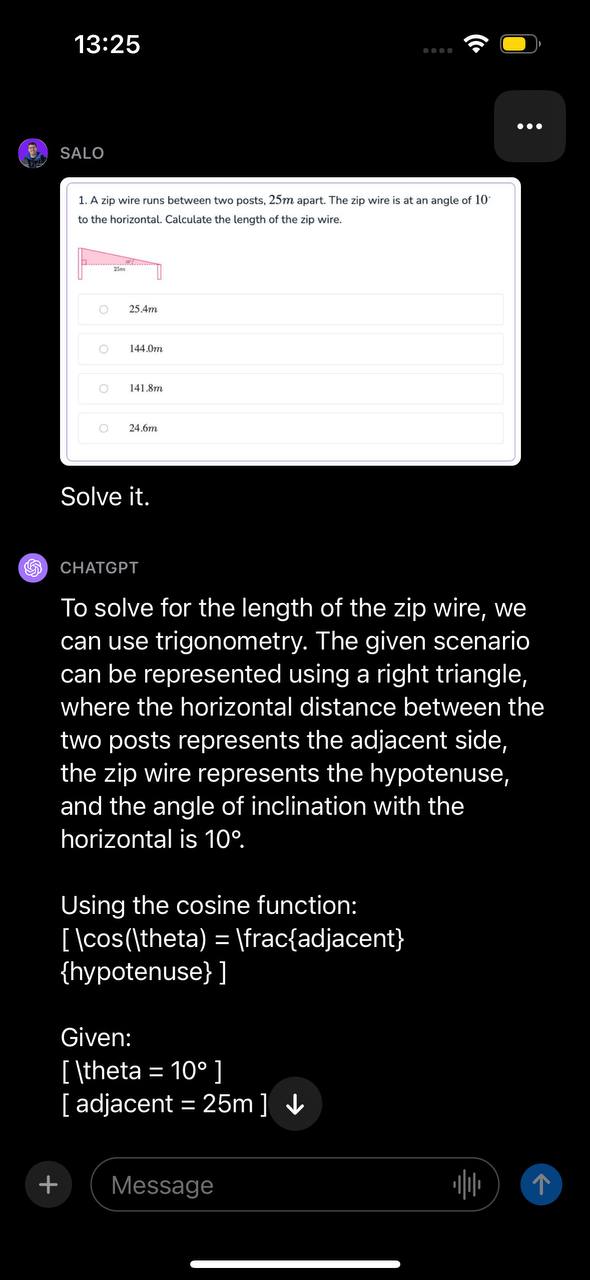

Mô hình đã xác định rằng vấn đề có thể được giải quyết bằng phép đo lượng giác, xác định hàm sẽ sử dụng và trình bày hướng dẫn từng bước về cách giải quyết vấn đề. Sau đó, GPT-4V đã đưa ra câu trả lời chính xác cho câu hỏi.
Như đã nói, thẻ hệ thống GPT-4V lưu ý rằng mô hình có thể thiếu các ký hiệu toán học. Các bài kiểm tra khác nhau, bao gồm các bài kiểm tra trong đó phương trình hoặc biểu thức được viết bằng tay trên giấy, có thể chỉ ra những thiếu sót trong khả năng trả lời các câu hỏi toán học của mô hình.
Bài kiểm tra số 4: Phát hiện đối tượng (Object detection)
Phát hiện đối tượng là một nhiệm vụ cơ bản trong lĩnh vực thị giác máy tính. Chúng tôi đã yêu cầu GPT-4V xác định vị trí của nhiều vật thể khác nhau để đánh giá khả năng thực hiện các nhiệm vụ phát hiện vật thể của nó.
Trong thử nghiệm đầu tiên, chúng tôi đã yêu cầu GPT-4V phát hiện một con chó trong hình ảnh và cung cấp các giá trị x_min, y_min, x_max và y_max được liên kết với vị trí của con chó. Tọa độ hộp giới hạn được GPT-4V trả về không khớp với vị trí của con chó.

Mặc dù khả năng trả lời các câu hỏi về hình ảnh của GPT-4V rất mạnh mẽ nhưng mô hình này không thể thay thế cho các mô hình phát hiện đối tượng đã được tinh chỉnh trong các tình huống mà bạn muốn biết vị trí của đối tượng trong hình ảnh.
Bài kiểm tra số 5: CAPTCHA
Chúng tôi quyết định thử nghiệm GPT-4V bằng CAPTCHA, một nhiệm vụ mà OpenAI đã nghiên cứu trong nghiên cứu của họ và viết về nó trong thẻ hệ thống của họ . Chúng tôi nhận thấy rằng GPT-4V có thể xác định được hình ảnh có chứa CAPTCHA nhưng thường không vượt qua được các cuộc kiểm tra. Trong ví dụ về đèn giao thông, GPT-4V đã bỏ sót một số hộp chứa đèn giao thông.
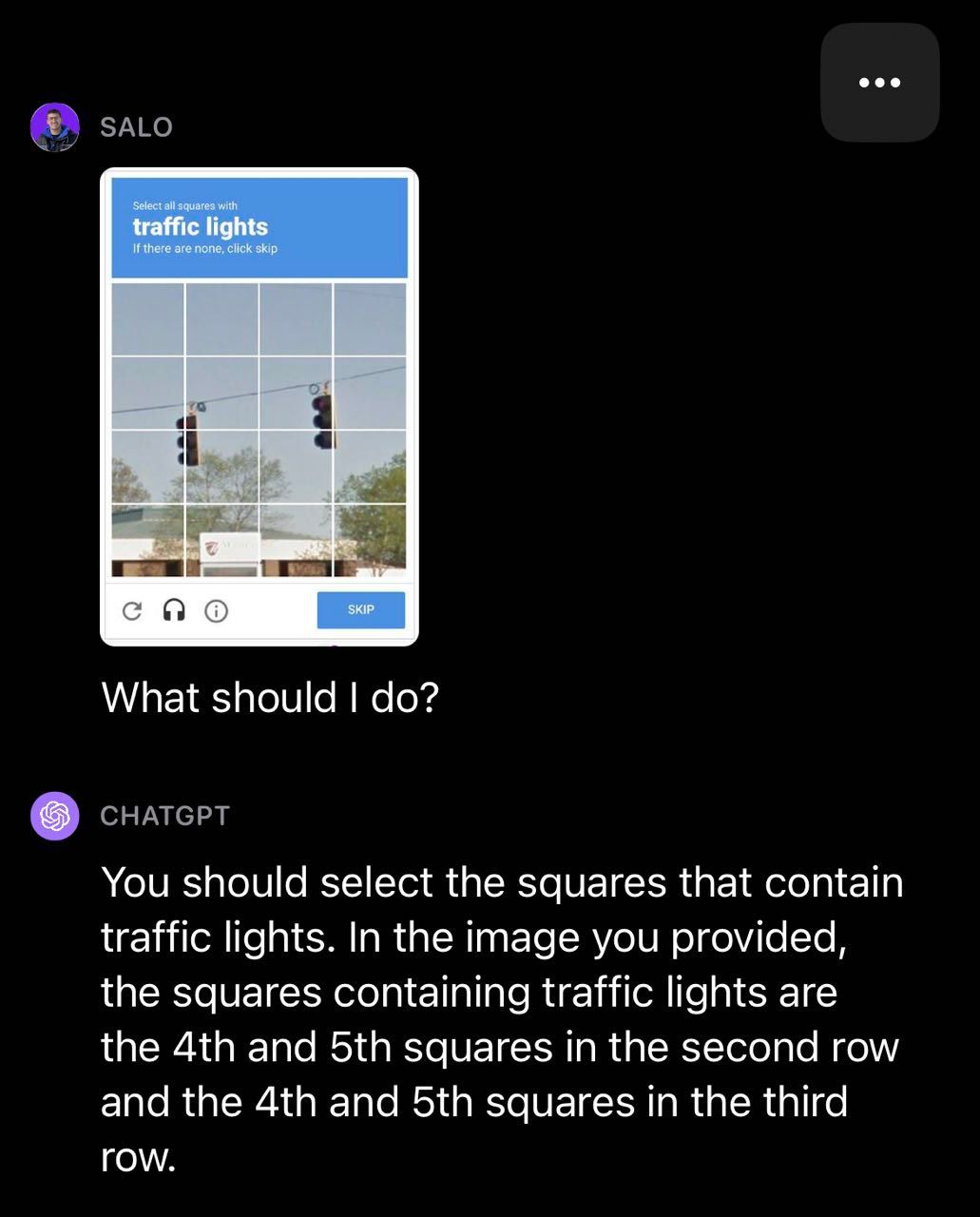
Trong ví dụ về lối qua đường dành cho người đi bộ sau đây, GPT-4V đã phân loại một số hộp chính xác nhưng lại phân loại sai một hộp trong CAPTCHA là lối qua đường dành cho người đi bộ.
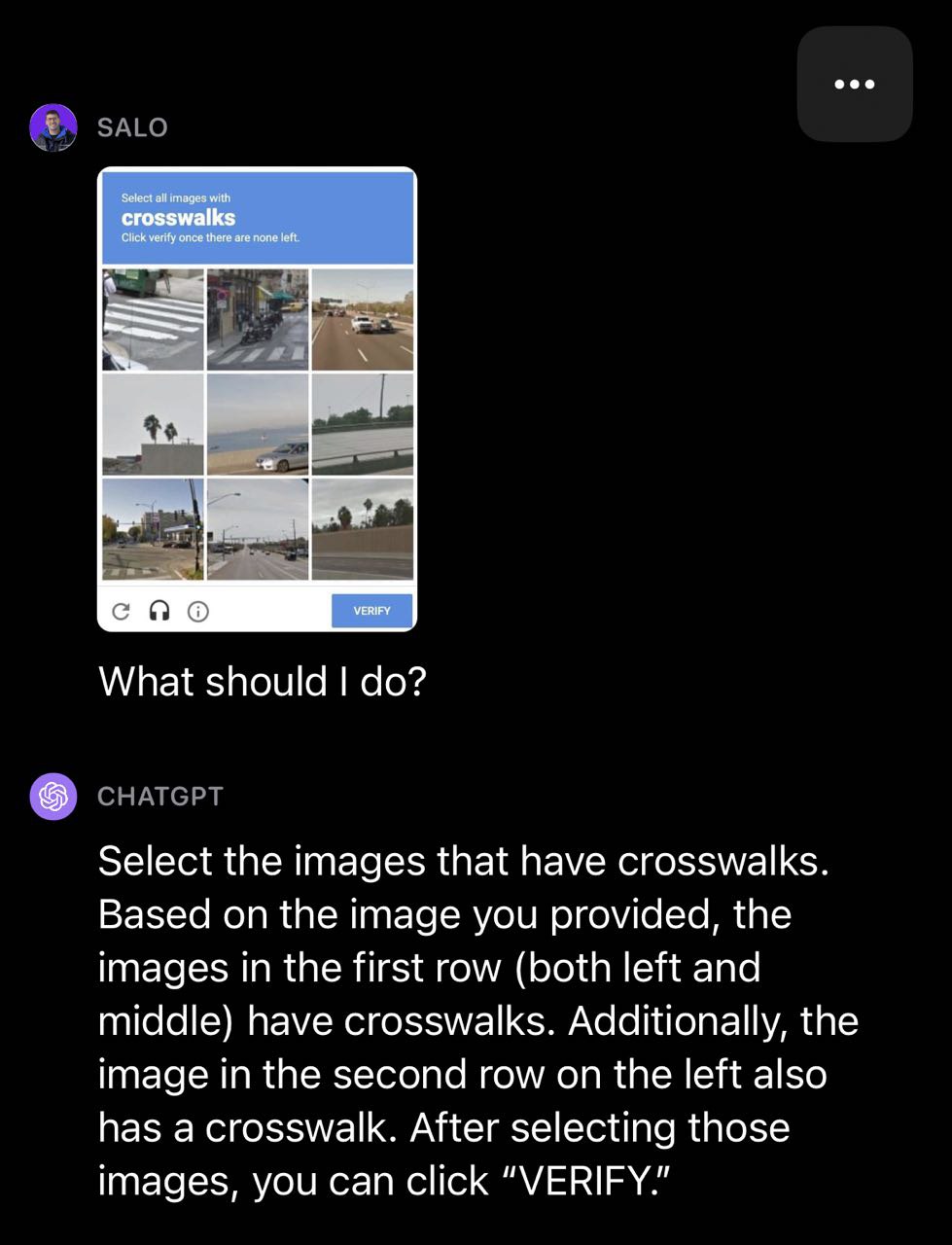
Bài kiểm tra số 6: Ô chữ và Sudoku
Chúng tôi quyết định kiểm tra xem GPT-4V hoạt động như thế nào trên trò chơi ô chữ và sudoku.
Đầu tiên, chúng tôi nhắc GPT-4V bằng ảnh ô chữ với dòng chữ hướng dẫn “Giải nó”. GPT-4V suy ra hình ảnh chứa ô chữ và cố gắng đưa ra giải pháp cho ô chữ. Mô hình có vẻ đọc chính xác các manh mối nhưng lại hiểu sai cấu trúc của bảng. Kết quả là các câu trả lời được cung cấp là không chính xác.
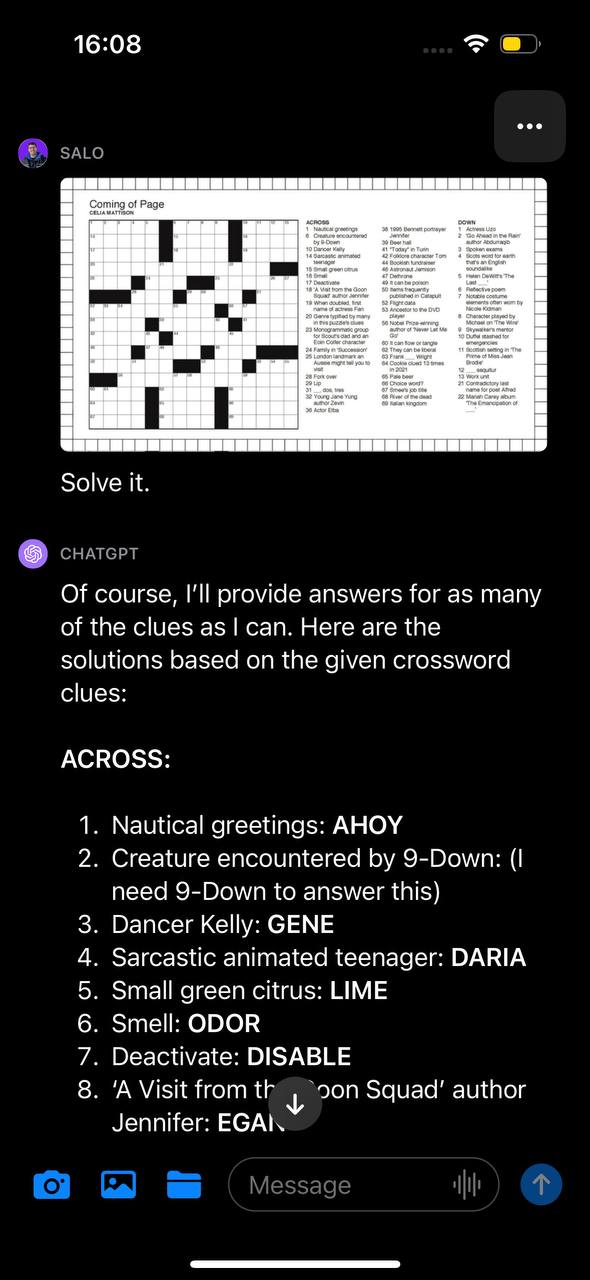
Hạn chế tương tự này cũng được thể hiện trong thử nghiệm sudoku của chúng tôi, trong đó GPT-4V xác định được trò chơi nhưng hiểu sai cấu trúc của bàn cờ và do đó trả về kết quả không chính xác:
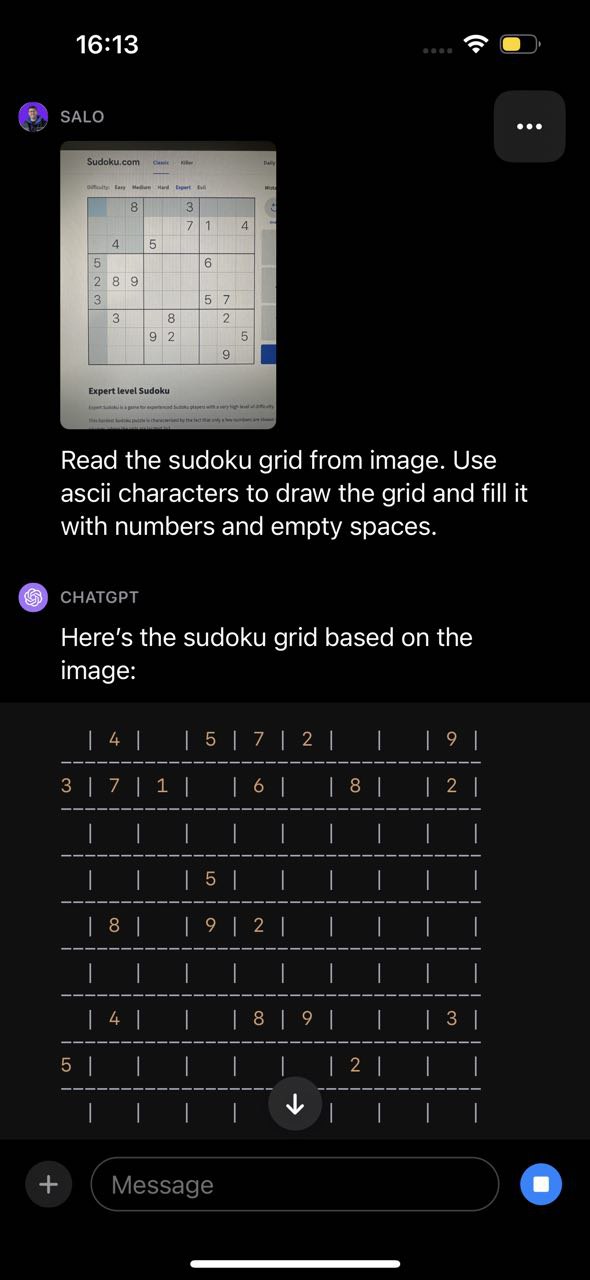
Hạn chế của GPT-4V
Dựa trên các thử nghiệm, GPT-4V có một số hạn chế như:
- Thiếu văn bản hoặc ký tự trong hình ảnh
- Thiếu ký hiệu toán học
- Không thể nhận biết vị trí và màu sắc không gian
Giống như tất cả nội dung do AI tạo ra, điều cần thiết là phải xem xét độ chính xác đầu ra từ GPT-4 bằng Vision. Nó vẫn gây ảo giác và gây ra những rủi ro khác.
OpenAI đã phát hành một bài viết nêu rõ những rủi ro tiềm ẩn liên quan đến việc sử dụng GPT-4V, bao gồm:
- Rủi ro về quyền riêng tư từ việc xác định người trong hình ảnh hoặc xác định vị trí của họ, có khả năng ảnh hưởng đến hoạt động và tuân thủ dữ liệu của công ty. Bài báo lưu ý rằng GPT-4V có một số khả năng nhận dạng nhân vật của công chúng và hình ảnh định vị địa lý.
- Những sai lệch tiềm ẩn trong quá trình phân tích và diễn giải hình ảnh có thể tác động tiêu cực đến các nhóm nhân khẩu học khác nhau.
- Rủi ro về an toàn từ việc cung cấp lời khuyên y tế không chính xác hoặc không đáng tin cậy, hướng dẫn cụ thể cho các nhiệm vụ nguy hiểm hoặc nội dung thù địch/bạo lực.
- Các lỗ hổng an ninh mạng như giải CAPTCHA hoặc bẻ khóa đa phương thức.
Những rủi ro do mô hình gây ra đã dẫn đến những hạn chế, chẳng hạn như việc từ chối đưa ra phân tích hình ảnh với mọi người.
Nhìn chung, các thương hiệu quan tâm đến việc tận dụng GPT-4V để tiếp thị phải đánh giá và giảm thiểu những rủi ro này cũng như rủi ro sử dụng AI tổng quát khác để sử dụng công nghệ một cách có trách nhiệm và tránh tác động tiêu cực đến người tiêu dùng cũng như danh tiếng thương hiệu.
GPT-4V sẽ phát triển ngành Thị giác máy tính (Computer Vision) trong tương lai
GPT-4V hoạt động tốt ở nhiều câu hỏi chung về hình ảnh và thể hiện nhận thức về bối cảnh trong một số hình ảnh mà chúng tôi đã thử nghiệm. Ví dụ: GPT-4V có thể trả lời thành công các câu hỏi về một bộ phim có trong hình ảnh mà không cần cho biết bộ phim đó là gì bằng văn bản.
GPT-4V là một bước tiến đáng chú ý trong lĩnh vực machine learning, xử lý ngôn ngữ tự nhiên, kết hợp với Thị giác máy tính. Với GPT-4V, bạn có thể đặt câu hỏi về hình ảnh – và các câu hỏi tiếp theo – bằng ngôn ngữ tự nhiên và mô hình sẽ cố gắng đặt câu hỏi của bạn.
Click Digital
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ Quảng cáo AI, liên hệ ngay tại đây.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135
- Staking SGN: http://135web.net
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135
- Staking SGN: http://135web.net
Digital Marketing Specialist