
Bạn có từng cố gắng ăn hết một chiếc bánh pizza siêu to khổng lồ và nhận ra rằng bạn cần phải chia nhỏ nó ra để ăn cho dễ? Chunking trong Machine Learning cũng hoạt động theo cách tương tự như vậy! Thay vì bắt máy tính “nhai” cả khối dữ liệu khổng lồ một lúc, chúng ta chia nhỏ dữ liệu thành những phần dễ tiêu hóa hơn.
Table of Contents
Chunking là gì?
Chunking đơn giản là chia nhỏ dữ liệu thành các “khối” (chunks) có kích thước vừa phải. Thay vì xử lý toàn bộ dữ liệu cùng một lúc, các mô hình ngôn ngữ lớn (LLMs) chỉ xử lý từng phần nhỏ hơn, giúp chúng hoạt động “bớt căng thẳng” và hiệu quả hơn về mặt tính toán.

Ví dụ:
- Hãy tưởng tượng bạn có một file tài liệu dài 100 trang. Nếu bạn đưa cả tài liệu này cho LLM xử lý, nó sẽ “bối rối” và không thể xử lý hết. Chia nhỏ tài liệu thành các câu hoặc đoạn văn ngắn hơn sẽ giúp LLM dễ dàng tiếp nhận thông tin hơn.
- Tương tự, khi bạn có một tấm ảnh độ phân giải cao 4K, bạn không thể đưa toàn bộ ảnh cho AI xử lý cùng lúc. Chunking sẽ giúp chia nhỏ bức ảnh thành các mảnh nhỏ, để AI có thể phân tích từng phần một cách hiệu quả.
Bảng so sánh các kỹ thuật chunking trong RAG:
| Kỹ thuật | Cách thức | Ưu điểm | Nhược điểm |
| Chunking truyền thống | Chia nhỏ tài liệu theo kích thước cố định (ví dụ: 512 tokens) | Dễ dàng cài đặt | Mất ngữ cảnh |
| Sliding window | Chia nhỏ tài liệu với các cửa sổ trượt chồng lên nhau | Giữ được một phần ngữ cảnh | Có thể tạo ra nhiều chunk trùng lặp |
| Multiple context window lengths | Chia nhỏ tài liệu với các độ dài cửa sổ khác nhau | Giữ được ngữ cảnh tốt hơn | Cần nhiều tài nguyên hơn |
| Multi-pass document scans | Quét tài liệu nhiều lần với các độ dài cửa sổ khác nhau | Giữ được ngữ cảnh tốt nhất | Rất tốn thời gian và tài nguyên |
| Late Chunking | Xử lý toàn bộ văn bản trước khi tạo embeddings | Giữ được ngữ cảnh tốt nhất, hiệu quả hơn | Phức tạp hơn, cần nhiều tài nguyên |
Late Chunking là gì?
Late Chunking là một kỹ thuật nâng cao của chunking. Thay vì chia nhỏ tài liệu trước khi tạo embeddings, Late Chunking xử lý toàn bộ văn bản trước khi tạo embeddings cho từng chunk. Điều này giúp embeddings của mỗi chunk sẽ giàu ngữ cảnh của toàn bộ tài liệu, giữ được những liên kết quan trọng giữa các phần thông tin.
So sánh giữa Chunking truyền thống và Late Chunking:
| Phương pháp | Cách thức | Ưu điểm | Nhược điểm |
| Chunking truyền thống | Chia nhỏ tài liệu trước khi tạo embeddings | Dễ dàng cài đặt | Mất ngữ cảnh |
| Late Chunking | Xử lý toàn bộ văn bản trước khi tạo embeddings | Giữ được ngữ cảnh | Phức tạp hơn |
Chunking cơ bản trong RAG
Trong Retrieval-Augmented Generation (RAG), chunking là quá trình chia một tài liệu dài thành các “chunks” nhỏ hơn (mỗi chunk chứa khoảng 512 token). Điều này rất quan trọng vì các LLMs thường bị giới hạn về lượng văn bản có thể xử lý cùng một lúc. Bằng cách chia tài liệu thành các chunk nhỏ, mỗi phần có thể được lưu trữ riêng lẻ trong Vector Database.
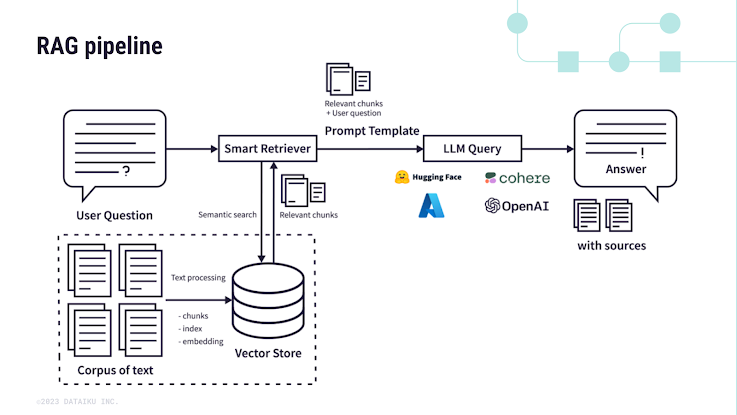
Các bước trong hệ thống RAG cơ bản:
- Chia nhỏ tài liệu: Tài liệu được chia thành các chunks nhỏ hơn (ví dụ: 512 tokens mỗi chunk).
- Tạo embeddings: Mỗi chunk được mã hóa thành một vector biểu diễn.
- Lưu trữ embeddings: Các vector này được lưu trữ trong một Vector Database.
- Truy xuất thông tin: Khi người dùng đưa ra một câu hỏi, Embedding Model sẽ mã hóa câu hỏi đó thành một vector.
- Tìm kiếm chunk phù hợp: Vector này sau đó được sử dụng để tìm kiếm và truy xuất các chunks văn bản phù hợp nhất từ Vector Database.
- Tổng hợp câu trả lời: Những chunk được truy xuất này sẽ được đưa vào LLM để tổng hợp một câu trả lời dựa trên thông tin chứa trong các chunks đó.
Hạn chế của kỹ thuật chunking cơ bản
Các phương pháp chunking truyền thống thường dẫn đến việc làm mất đi các kết nối quan trọng giữa các phần khác nhau của văn bản. Ví dụ, khi bạn cắt tài liệu ra thành các đoạn nhỏ, các đoạn đó sẽ bị cô lập và mất đi mối quan hệ với các đoạn khác. Embedding vector của những đoạn bị cô lập đó sẽ chỉ tổng hợp được thông tin nội bộ trong đoạn, nhưng không tổng hợp được thông tin liên quan giữa các đoạn khác nhau.
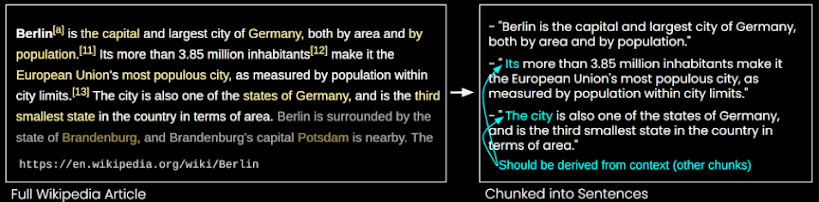
Ví dụ:
Hãy xem đoạn văn sau:
“Berlin là thủ đô và thành phố lớn nhất của Đức, cả về diện tích và dân số. Hơn 3,85 triệu cư dân của nó làm cho nó trở thành thành phố đông dân nhất Liên minh Châu Âu, được đo bằng dân số trong giới hạn thành phố. Thành phố cũng là một trong những bang của Đức, và là bang nhỏ thứ ba của đất nước về diện tích.”
Nếu chúng ta chia đoạn văn này thành các câu riêng lẻ, các từ như “nó” và “thành phố” sẽ mất đi ngữ cảnh liên kết với “Berlin”, làm cho LLM khó hiểu ý nghĩa thực sự của câu.
Late Chunking là giải pháp cho vấn đề này
Late Chunking giải quyết vấn đề mất ngữ cảnh bằng cách áp dụng transformer layer của embedding model lên toàn bộ văn bản trước khi chia nhỏ thành các chunks. Cách tiếp cận này giúp mỗi chunk được tạo ra đã bao gồm thông tin ngữ cảnh từ toàn bộ văn bản, giúp LLM hiểu rõ hơn ý nghĩa của từng đoạn.
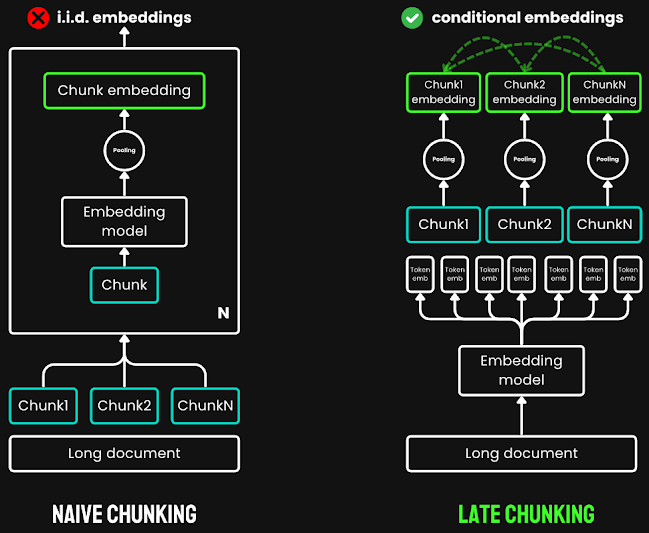
Ví dụ:
Khi áp dụng Late Chunking cho đoạn văn về Berlin ở trên, các vector biểu diễn cho “thành phố” giờ đây sẽ chứa thông tin của “Berlin” được nhắc đến trước đó, giúp LLM dễ dàng xác định mối liên kết giữa các câu.

Cách thức hoạt động của Late Chunking
Late Chunking hoạt động bằng cách:
- Xử lý toàn bộ văn bản: Áp dụng transformer layer của embedding model lên toàn bộ văn bản.
- Tạo embeddings cho từng token: Tạo ra một chuỗi các vector biểu diễn cho mỗi token.
- Chia nhỏ thành chunks: Chia chuỗi các vector token này thành các chunks dựa trên các boundary cues (ví dụ: câu, đoạn văn).
- Tạo embeddings cho từng chunk: Áp dụng mean pooling trên các vector token trong mỗi chunk để tạo ra một embedding vector cho chunk đó.
Late Chunking giữ lại ngữ cảnh của toàn bộ văn bản trong mỗi chunk, giúp LLM có thể hiểu được các mối liên kết giữa các phần thông tin.
Ưu điểm của Late Chunking
- Giữ được ngữ cảnh: Late Chunking giúp giữ được thông tin ngữ cảnh của toàn bộ tài liệu trong mỗi chunk.
- Hiệu quả hơn: Late Chunking hiệu quả hơn trong việc truy xuất thông tin so với các phương pháp chunking truyền thống.
- Dễ dàng cài đặt: Late Chunking có thể được cài đặt dễ dàng bằng cách thay đổi một vài dòng code trong embedding model.
Nhược điểm của Late Chunking
Late Chunking là một kỹ thuật tiềm năng, nhưng nó cũng có một số điểm yếu cần lưu ý:
- Độ phức tạp: Late Chunking phức tạp hơn chunking truyền thống, đòi hỏi việc xử lý toàn bộ văn bản trước khi tạo embeddings. Điều này có thể dẫn đến thời gian xử lý lâu hơn, đặc biệt là đối với các tài liệu dài.
- Yêu cầu về tài nguyên: Late Chunking cần sử dụng các long-context embedding models, thường đòi hỏi nhiều tài nguyên tính toán hơn so với các embedding models truyền thống.
- Cần điều chỉnh kỹ thuật: Tùy thuộc vào loại tài liệu và mục đích sử dụng, có thể cần phải điều chỉnh kỹ thuật chunking và lựa chọn boundary cues phù hợp để đạt hiệu quả tối ưu.
- Hiệu quả không đồng đều: Hiệu quả của Late Chunking có thể không đồng đều đối với các loại tài liệu khác nhau. Ví dụ, nó có thể hiệu quả hơn đối với các tài liệu có cấu trúc rõ ràng, nhưng có thể kém hiệu quả hơn đối với các tài liệu có cấu trúc phức tạp hoặc ít liên kết ngữ cảnh.
- Chưa có nhiều thử nghiệm: Late Chunking là một kỹ thuật còn khá mới, nên vẫn chưa có nhiều thử nghiệm và nghiên cứu về hiệu quả của nó trong thực tế.
Dù có những điểm yếu, Late Chunking vẫn được xem là một kỹ thuật tiềm năng trong việc cải thiện khả năng xử lý thông tin của RAG. Với sự phát triển của công nghệ và các nghiên cứu thêm về Late Chunking, hy vọng những hạn chế này sẽ được khắc phục trong tương lai.
Bảng so sánh Late Chunking với Naive Chunking và ColBERT
| Kỹ thuật | Cách thức | Ưu điểm | Nhược điểm |
| Naive Chunking | Chia nhỏ tài liệu trước khi tạo embeddings | Dễ dàng cài đặt, ít tốn tài nguyên | Mất ngữ cảnh |
| Late Chunking | Xử lý toàn bộ văn bản trước khi tạo embeddings | Giữ được ngữ cảnh, hiệu quả hơn | Phức tạp hơn, cần nhiều tài nguyên |
| ColBERT | Không chia nhỏ tài liệu, so sánh trực tiếp các token | Hiệu quả cao, giữ được ngữ cảnh tốt | Tốn nhiều tài nguyên, khó cài đặt |
Nhận xét về chủ đề
Late Chunking là một kỹ thuật hứa hẹn trong việc cải thiện khả năng xử lý thông tin của RAG. Có thể thấy rằng, Late Chunking giúp giải quyết được một trong những vấn đề lớn nhất của chunking truyền thống – mất ngữ cảnh. Mặc dù Late Chunking đang được nghiên cứu và phát triển, nhưng nó đã chứng minh được hiệu quả trong nhiều thử nghiệm, mở ra những tiềm năng lớn cho tương lai của RAG.
Lưu ý
- Long-context embedding models: Late Chunking yêu cầu sử dụng long-context embedding models, có khả năng xử lý một lượng lớn token (ví dụ: 8192 tokens).
- Boundary cues: Boundary cues (ví dụ: câu, đoạn văn) được sử dụng để chia nhỏ các vector token thành các chunks.
Tài liệu tham khảo
- JinaAI: Late Chunking: https://jina.ai/blog/late-chunking-long-context-embedding-models/
- GitHub repo: https://github.com/jina-ai/late-chunking
- Colab Notebook: https://colab.research.google.com/drive/15vNZb6AsU7byjYoaEtXuNu567JWNzXOz
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist