 chia mô hình thành nhiều “chuyên gia” đảm nhận nhiệm vụ riêng biệt: Cải thiện hiệu suất mô hình với chi phí tối ưu")
Tóm tắt: Mixture of Experts (MoE) là một kỹ thuật giúp cải thiện hiệu suất của mô hình máy học mà không cần phải tăng kích thước của mô hình một cách quá mức. MoE hoạt động bằng cách chia mô hình thành nhiều “chuyên gia” (experts), mỗi chuyên gia đảm nhiệm một nhiệm vụ riêng biệt. Khi xử lý dữ liệu, chỉ những chuyên gia liên quan sẽ được kích hoạt, giúp giảm thiểu lượng tính toán và thời gian thực thi. Bài viết này sẽ giải thích cho bạn đọc chi tiết về MoE và cơ chế hoạt động, cũng như điểm mạnh, điểm yếu và các ứng dụng của nó.
Table of Contents
Mixture of Experts là gì?
Bạn muốn cải thiện hiệu suất của mô hình? Câu trả lời đơn giản là: Tăng kích thước của nó! Đó là lý do vì sao bạn thấy các mô hình ngôn ngữ lớn (LLMs) ngày càng trở nên khổng lồ. Nhưng kích thước không thể cứ tăng mãi được. Mô hình càng lớn, việc huấn luyện càng tốn kém thời gian và tài nguyên. Với ngân sách hạn chế, bạn cần có giải pháp để cải thiện hiệu suất mô hình mà không phải tăng kích thước quá mức.
Mixture of Experts (MoE) là một kỹ thuật độc đáo, cho phép bạn tăng kích thước của mô hình mà không làm tăng quá nhiều chi phí huấn luyện. MoE có thể đạt được hiệu suất tương đương với mô hình dense truyền thống, nhưng thời gian thực thi (inference time) nhanh hơn rất nhiều.
Bảng so sánh MoE với mô hình Dense truyền thống
| Đặc điểm | MoE | Mô hình Dense truyền thống |
| Kích thước mô hình | Có thể lớn hơn, nhưng chi phí huấn luyện thấp hơn | Cần kích thước lớn để đạt hiệu suất cao |
| Cơ chế hoạt động | Chia mô hình thành nhiều “chuyên gia” (experts) | Sử dụng tất cả các tham số trong mô hình |
| Thời gian huấn luyện | Nhanh hơn | Chậm hơn |
| Thời gian thực thi (Inference time) | Nhanh hơn | Chậm hơn |
| Yêu cầu về RAM | Cao hơn | Thấp hơn |
| Khả năng tổng quát hóa | Có thể khó khăn hơn | Thường dễ tổng quát hóa hơn |
| Khả năng xử lý dữ liệu phức tạp | Tốt hơn | Có thể kém hiệu quả hơn |
| Ứng dụng | LLM, xử lý ngôn ngữ tự nhiên, dịch máy, tóm tắt văn bản, … | Xử lý hình ảnh, nhận dạng giọng nói, phân loại dữ liệu, … |
Lưu ý: Bảng này cung cấp một so sánh chung về MoE và mô hình Dense truyền thống. Việc lựa chọn loại mô hình nào phụ thuộc vào yêu cầu cụ thể của bài toán và tài nguyên có sẵn.
Các ứng dụng của Mixture of Experts (MoE)
| Lĩnh vực | Ứng dụng | Lợi ích |
| Xử lý ngôn ngữ tự nhiên (NLP) | – Dịch máy – Tóm tắt văn bản – Phân loại văn bản – Sinh văn bản – Hỏi đáp | – Cải thiện chất lượng dịch – Tóm tắt chính xác hơn – Phân loại chính xác hơn – Sinh văn bản tự nhiên hơn – Đáp ứng chính xác hơn |
| Xử lý ảnh | – Phân loại ảnh – Phát hiện đối tượng – Sinh ảnh | – Phân loại chính xác hơn – Phát hiện đối tượng chính xác hơn – Sinh ảnh chất lượng cao hơn |
| Âm nhạc | – Sinh nhạc – Phân loại nhạc – Phân tích âm nhạc | – Sinh nhạc độc đáo và sáng tạo hơn – Phân loại nhạc chính xác hơn – Phân tích âm nhạc chi tiết hơn |
| Khoa học máy tính | – Huấn luyện mô hình lớn – Tối ưu hóa thuật toán – Xử lý dữ liệu lớn | – Giảm thời gian huấn luyện – Tăng hiệu quả thuật toán – Xử lý dữ liệu hiệu quả hơn |
| Y tế | – Chẩn đoán bệnh – Phân tích dữ liệu y tế – Phát triển thuốc | – Chẩn đoán chính xác hơn – Phân tích dữ liệu hiệu quả hơn – Phát triển thuốc hiệu quả hơn |
Lưu ý: Bảng này chỉ liệt kê một số ứng dụng chính của MoE. MoE có tiềm năng ứng dụng trong nhiều lĩnh vực khác, tùy thuộc vào yêu cầu cụ thể của bài toán và sự sáng tạo của các nhà nghiên cứu.
Cấu trúc của MoE
MoE có hai thành phần chính:
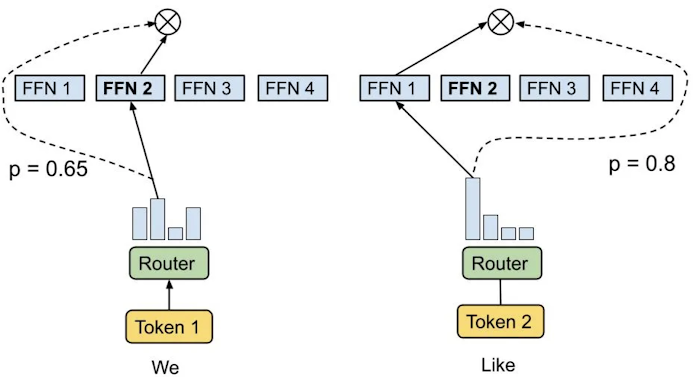
- Sparse MoE layers: Thay vì sử dụng các lớp feed-forward dense (FFN) rất lớn và tốn kém chi phí tính toán, MoE sẽ chia nó thành các “cục” nhỏ hơn, mỗi “cục” được gọi là một “expert”. Mỗi expert sẽ thực hiện một nhiệm vụ khác nhau. Dựa vào dữ liệu đầu vào, chỉ những experts liên quan mới được kích hoạt để xử lý input. Ví dụ, nếu input là những đoạn văn về màu sắc, thì những experts chuyên xử lý màu sắc sẽ được chọn, thay vì những experts chuyên xử lý về âm nhạc hoặc điện ảnh Ấn Độ. Mỗi “expert” có thể là một FFN nhỏ hơn, một mạng lưới phức tạp hơn, hoặc thậm chí là một MoE layer khác – tức là MoE lồng trong MoE!
- Router/Gate Network: Router đóng vai trò giống như một cảnh sát phân luồng giao thông. Nó quyết định xem token nào sẽ được gửi đến expert nào để xử lý. Router được huấn luyện cùng với các phần khác của mô hình trong quá trình training. Nó sẽ học cách phân bổ token cho các experts một cách hiệu quả dựa trên dữ liệu huấn luyện.
Hình minh họa:
Ứng dụng của MoE trong Transformer
Transformer là một mô hình kiến trúc mạng thần kinh nổi tiếng được sử dụng rộng rãi trong các LLM hiện nay. Transformer bao gồm hai phần chính: encoder và decoder.
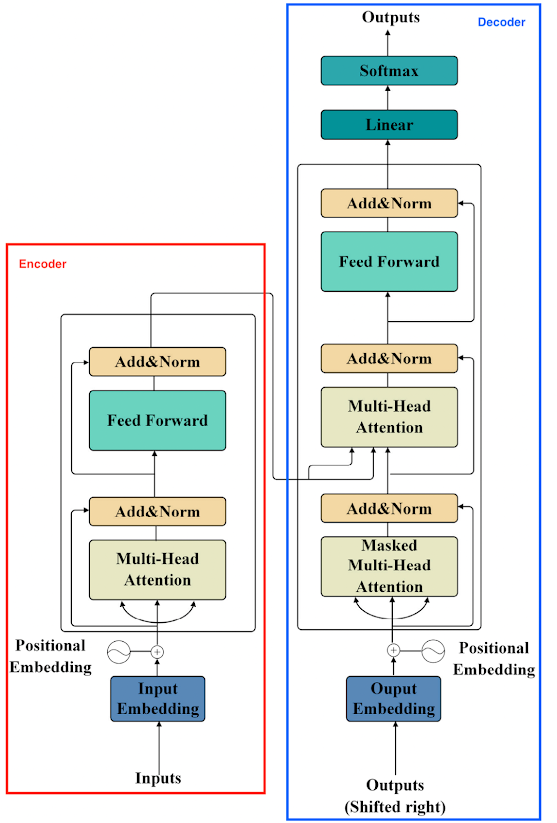
Cả encoder và decoder đều có một thành phần gọi là “Feed Forward”, đó chính là FFN layer. MoE có thể được sử dụng thay thế cho FFN layer trong Transformer.
Tóm lại: Ta thay thế mỗi lớp FFN của Transformer bằng một lớp MoE (bao gồm Sparse MoE layer và Router).
Điểm mạnh của MoE
- Thời gian huấn luyện và thực thi nhanh hơn: So với mô hình cùng kích thước sử dụng FFN dense, MoE có thời gian huấn luyện và thực thi nhanh hơn. Điều này là do MoE chỉ kích hoạt một phần nhỏ các experts trong mô hình, dẫn đến lượng tính toán giảm đi đáng kể.
- Tiết kiệm tài nguyên: Việc chỉ kích hoạt những experts liên quan giúp giảm thiểu lượng tính toán và tài nguyên cần sử dụng, giúp tiết kiệm chi phí huấn luyện.
Điểm yếu của MoE
- Khó khăn trong việc tổng quát hóa (generalize): Thực nghiệm cho thấy MoE có thể gặp khó khăn trong việc tổng quát hóa quá trình huấn luyện và dễ bị overfit. Điều này có thể xảy ra do việc sử dụng các experts chuyên biệt dẫn đến mô hình học được các pattern rất cụ thể của dữ liệu huấn luyện.
- Yêu cầu về RAM cao: Mặc dù thời gian thực thi nhanh hơn, nhưng MoE cần tải tất cả tham số của các experts vào RAM, điều này dẫn đến yêu cầu về RAM cao hơn.
Bảng tổng hợp ưu nhược điểm của kỹ thuật Mixture of Experts (MoE)
| Ưu điểm | Nhược điểm |
| Hiệu suất cao hơn: MoE có thể đạt được hiệu suất tương đương với mô hình dense truyền thống, nhưng với kích thước mô hình nhỏ hơn. | Khó khăn trong việc tổng quát hóa: MoE có thể gặp khó khăn trong việc tổng quát hóa quá trình huấn luyện và dễ bị overfit. |
| Thời gian huấn luyện nhanh hơn: Việc chỉ kích hoạt những experts liên quan giúp giảm thiểu lượng tính toán và tài nguyên cần sử dụng, giúp tiết kiệm thời gian huấn luyện. | Yêu cầu về RAM cao hơn: Mặc dù thời gian thực thi nhanh hơn, nhưng MoE cần tải tất cả tham số của các experts vào RAM, điều này dẫn đến yêu cầu về RAM cao hơn. |
| Tiết kiệm tài nguyên: MoE sử dụng sparsity và conditional computation, giúp giảm thiểu lượng tính toán và tài nguyên cần sử dụng. | Phức tạp trong triển khai: MoE thường phức tạp hơn trong triển khai so với mô hình dense truyền thống. |
| Linh hoạt hơn: MoE cho phép chúng ta sử dụng các experts chuyên biệt cho các nhiệm vụ khác nhau, giúp mô hình linh hoạt hơn trong việc xử lý dữ liệu phức tạp. | Khó khăn trong việc giám sát và gỡ lỗi: Việc sử dụng nhiều experts khiến việc giám sát và gỡ lỗi mô hình trở nên khó khăn hơn. |
Lưu ý: Bảng này cung cấp một cái nhìn tổng quan về ưu nhược điểm của MoE. Việc lựa chọn sử dụng MoE hay không phụ thuộc vào yêu cầu cụ thể của bài toán và tài nguyên có sẵn.
Bảng so sánh các phương pháp huấn luyện MoE
| Phương pháp | Mô tả | Ưu điểm | Nhược điểm |
| Huấn luyện đồng thời (Joint Training) | Tất cả các experts và router được huấn luyện cùng lúc. | Đơn giản, hiệu quả. | Có thể dẫn đến việc các experts cạnh tranh với nhau, làm giảm hiệu quả huấn luyện. |
| Huấn luyện riêng biệt (Separate Training) | Huấn luyện từng expert riêng biệt trước, sau đó huấn luyện router. | Dễ dàng quản lý, có thể sử dụng các kỹ thuật huấn luyện riêng biệt cho mỗi expert. | Có thể dẫn đến việc các experts không tương thích với nhau. |
| Huấn luyện luân phiên (Alternating Training) | Luân phiên huấn luyện các experts và router. | Giúp các experts và router phù hợp với nhau hơn. | Có thể dẫn đến việc huấn luyện chậm hơn. |
| Huấn luyện dựa trên gradient (Gradient-based Training) | Sử dụng gradient descent để tối ưu hóa các tham số của experts và router. | Phổ biến, hiệu quả. | Có thể bị mắc kẹt trong tối ưu cục bộ. |
| Huấn luyện dựa trên evolutionary algorithm (Evolutionary Algorithm Training) | Sử dụng các thuật toán tiến hóa để tìm kiếm các cấu hình experts và router tối ưu. | Khám phá được nhiều cấu hình hơn, có thể tránh tối ưu cục bộ. | Phức tạp hơn, có thể tốn nhiều thời gian hơn. |
Lưu ý: Bảng này cung cấp một so sánh chung về các phương pháp huấn luyện MoE. Việc lựa chọn phương pháp phù hợp phụ thuộc vào yêu cầu cụ thể của bài toán, tài nguyên có sẵn và kinh nghiệm của nhà nghiên cứu.
Bảng so sánh các framework hỗ trợ Mixture of Experts (MoE)
| Framework | Ngôn ngữ | Ưu điểm | Nhược điểm |
| TensorFlow | Python | – Hỗ trợ mạnh mẽ cho các mô hình deep learning. – Cung cấp các API linh hoạt để xây dựng và huấn luyện MoE. | – Có thể phức tạp đối với người mới bắt đầu. |
| PyTorch | Python | – Dễ học, sử dụng và gỡ lỗi. – Cộng đồng người dùng lớn, nhiều tài liệu hỗ trợ. | – Hỗ trợ cho MoE có thể không đầy đủ như TensorFlow. |
| JAX | Python | – Hiệu suất cao, hỗ trợ tốt cho việc tính toán trên GPU. – Cung cấp các API linh hoạt để xây dựng và huấn luyện MoE. | – Cộng đồng người dùng nhỏ hơn so với TensorFlow và PyTorch. |
| Hugging Face Transformers | Python | – Cung cấp các mô hình Transformer được huấn luyện sẵn. – Hỗ trợ MoE thông qua các lớp MoE và Router được tích hợp sẵn. | – Có thể bị hạn chế về khả năng tùy chỉnh. |
| DeepMind’s Haiku | Python | – Hỗ trợ MoE thông qua các lớp MoE và Router. – Cung cấp các công cụ hỗ trợ cho việc debug và profiling. | – Cộng đồng người dùng nhỏ hơn so với TensorFlow và PyTorch. |
Cơ chế hoạt động của MoE
Cơ chế hoạt động của Mixture of Experts (MoE) thật sự thông minh và hiệu quả. Thay vì sử dụng một mạng lưới thần kinh duy nhất, MoE chia mô hình thành nhiều “chuyên gia” (experts), mỗi chuyên gia đảm nhiệm một nhiệm vụ riêng biệt. Điều này giúp giảm tải cho mạng lưới chính, từ đó tăng tốc độ huấn luyện và thực thi. Router đóng vai trò như một bộ điều khiển thông minh, phân bổ nhiệm vụ cho các experts một cách hiệu quả dựa trên nội dung của dữ liệu đầu vào. Cơ chế này cho phép MoE tận dụng tối ưu khả năng của từng chuyên gia, mang đến hiệu suất cao hơn so với các mô hình truyền thống.
Sparsity, cơ chế gating,… là những yếu tố cốt lõi giúp MoE đạt được hiệu quả cao. Sparsity là khái niệm sử dụng một phần nhỏ các tham số của mô hình để xử lý dữ liệu, thay vì sử dụng toàn bộ như các mô hình truyền thống. Nhờ sparsity, MoE có thể giảm thiểu lượng tính toán, từ đó tiết kiệm thời gian và tài nguyên. Cơ chế gating, được thể hiện qua router, là bộ phận quyết định expert nào sẽ được kích hoạt dựa trên dữ liệu đầu vào. Router có thể sử dụng các kỹ thuật như softmax, noisy top-k gating, hay expert choice routing để phân bổ nhiệm vụ một cách hiệu quả. Sự kết hợp giữa sparsity và cơ chế gating tạo nên sức mạnh của MoE, cho phép mô hình học hiệu quả hơn và xử lý dữ liệu phức tạp một cách chính xác.
Sparsity trong MoE
Một trong những khái niệm quan trọng nhất của MoE đó là sparsity (tính thưa). Sparsity sử dụng ý tưởng conditional computation (tính toán có điều kiện). Khi đưa một input vào, chỉ có một phần nhỏ tham số của mô hình được sử dụng để xử lý input, trong khi các mô hình dense truyền thống sử dụng hết tất cả các tham số.
Sparsity được thực hiện thông qua router, nó quyết định experts nào của mô hình sẽ được kích hoạt cho một input cụ thể. Vậy làm sao để train cho router quyết định được experts nào là phù hợp với input nào?
Cơ chế gating của Router
Có rất nhiều cách để cài đặt cơ chế gating của router. Cách cơ bản nhất là sử dụng hàm softmax:
Giả sử input là x, ta có các experts E1, E2, …, En với n là tổng số experts. Output của MoE sẽ được tính bằng công thức sau:
y = ∑i=1n αi Ei(x)
αi là trọng số của expert Ei, tượng trưng cho mức độ liên quan của expert Ei với input hiện tại. Nếu αi=0, nghĩa là expert Ei không liên quan gì tới input hiện tại. Hàm softmax sẽ đảm bảo hai điều:
- αi > 0
- ∑ni=1 αi = 1
Hàm softmax giúp tạo ra một phân phối xác suất trên các outputs, ở đây chính là trọng số của từng expert. Với input hiện tại, giả sử ta nên sử dụng 80% của expert E1, 2% của expert E2, … thì hàm softmax sẽ tìm ra cho chúng ta α1=0.8, α2=0.02, …
Noisy Top-K Gating
Ngoài cách gating cơ bản bằng softmax, còn có các cách khác như Noisy Top-K Gating:
- Bước 1: Thêm nhiễu (noise) vào điểm số của mỗi expert:
Hi(x) = (w⊤ix) + N(0,1) ⋅ softplus(wnoise⊤ix)
x là input
w⊤ix là điểm liên quan của expert Ei đối với input x
N(0,1) là phân phối chuẩn (Standard Normal Distribution)
softplus là một hàm kích hoạt nhằm đảm bảo giá trị nhiễu luôn dương.
wnoise⊤ix là giá trị nhiễu mà ta muốn thêm vào cho expert Ei
- Bước 2: Chọn K experts có điểm số cao nhất:
TopK(H,k)i = {Hi if Hi thuộc top k giá trị lớn nhất, -∞ otherwise.}
Hi là điểm số đã thêm nhiễu của expert Ei được tính ở bước 1
k là số lượng experts mà mình muốn chọn
- Bước 3: Sử dụng Softmax lên k experts được chọn ở bước 2:
αi = eHi(x) / ∑kj=1 eHj(x)
Bằng cách chọn số k đủ nhỏ (VD: 1 hoặc 2), ta có thể huấn luyện và chạy inference nhanh hơn so với việc có nhiều experts được kích hoạt hơn (VD: 5 hoặc 6).
Các biến thể của MoE
Ngoài cấu trúc cơ bản, MoE còn có một số biến thể được phát triển để cải thiện hiệu suất và giải quyết các vấn đề cụ thể:
- Switch Transformer: Chỉ sử dụng duy nhất một expert trong MoE layer (k = 1), thay vì top-k experts.
- Expert Choice Routing: Router học cách chọn experts dựa trên nội dung của input, thay vì chỉ dựa trên vị trí của token.
Bảng so sánh các kỹ thuật gating trong MoE
| Kỹ thuật gating | Mô tả | Ưu điểm | Nhược điểm |
| Softmax Gating | Sử dụng hàm softmax để tính trọng số cho từng expert, đảm bảo tổng trọng số bằng 1. | Đơn giản, dễ triển khai. | Có thể bị ảnh hưởng bởi các giá trị ngoại lai. |
| Noisy Top-K Gating | Thêm nhiễu vào điểm số của các experts, chọn K experts có điểm số cao nhất và sử dụng softmax để tính trọng số. | Giúp mô hình khám phá nhiều experts hơn, giảm overfitting. | Phức tạp hơn softmax gating. |
| Expert Choice Routing | Router học cách chọn experts dựa trên nội dung của input, thay vì chỉ dựa trên vị trí của token. | Cho phép router linh hoạt hơn trong việc chọn experts phù hợp với input. | Yêu cầu nhiều dữ liệu huấn luyện hơn. |
Lưu ý: Bảng này cung cấp một so sánh chung về các kỹ thuật gating trong MoE. Việc lựa chọn kỹ thuật phù hợp phụ thuộc vào yêu cầu cụ thể của bài toán và tài nguyên có sẵn.
Bảng so sánh các biến thể của MoE
| Biến thể | Mô tả | Ưu điểm | Nhược điểm |
| MoE cơ bản | Sử dụng softmax gating để chọn K experts có điểm số cao nhất. | Đơn giản, dễ triển khai. | Có thể bị ảnh hưởng bởi các giá trị ngoại lai. |
| Switch Transformer | Chỉ sử dụng duy nhất một expert trong MoE layer (k = 1). | Giảm thiểu thời gian huấn luyện và thực thi. | Có thể hạn chế khả năng khám phá của mô hình. |
| Expert Choice Routing | Router học cách chọn experts dựa trên nội dung của input, thay vì chỉ dựa trên vị trí của token. | Cho phép router linh hoạt hơn trong việc chọn experts phù hợp với input. | Yêu cầu nhiều dữ liệu huấn luyện hơn. |
| Sparse Mixture of Experts (SparseMoE) | Sử dụng kỹ thuật sparsity để giảm thiểu lượng tính toán và tài nguyên cần sử dụng. | Tăng hiệu suất, giảm chi phí huấn luyện. | Có thể phức tạp hơn trong triển khai. |
| Mixture of Experts with Adaptive Routing (MoEAR) | Router học cách điều chỉnh số lượng experts được kích hoạt dựa trên độ phức tạp của input. | Tăng tính linh hoạt, hiệu quả hơn với các input phức tạp. | Yêu cầu nhiều dữ liệu huấn luyện hơn. |
Lưu ý: Bảng này cung cấp một so sánh chung về các biến thể của MoE. Việc lựa chọn biến thể phù hợp phụ thuộc vào yêu cầu cụ thể của bài toán và tài nguyên có sẵn.
Bảng tổng hợp các nghiên cứu nổi bật về Mixture of Experts (MoE)
| Nghiên cứu | Tác giả | Năm | Nội dung chính |
| Mixture of Experts | Jacobs, R. A., Jordan, M. I., & Nowlan, S. J. | 1991 | Giới thiệu khái niệm MoE và cơ chế gating ban đầu. |
| Switching Between Experts | Jordan, M. I., & Jacobs, R. A. | 1994 | Phát triển phương pháp huấn luyện MoE dựa trên gradient descent. |
| A Mixture of Experts Architecture for Pattern Recognition | Jordan, M. I., & Jacobs, R. A. | 1994 | Ứng dụng MoE vào nhận dạng mẫu. |
| Training Mixtures of Experts with the EM Algorithm | Jordan, M. I., & Jacobs, R. A. | 1994 | Sử dụng thuật toán EM để huấn luyện MoE. |
| Sparse Mixture of Experts: A Scalable and Efficient Architecture for Large-Scale Learning | Shazeer, N., et al. | 2017 | Giới thiệu SparseMoE, một biến thể hiệu quả của MoE cho việc học quy mô lớn. |
| Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity | Fedus, W., et al. | 2021 | Giới thiệu Switch Transformer, một kiến trúc MoE sử dụng chỉ một expert trong mỗi lớp. |
| Expert Choice Routing: Towards More Efficient and Interpretable Mixture of Experts Models | He, X., et al. | 2021 | Phát triển kỹ thuật Expert Choice Routing cho MoE. |
| MoE with Adaptive Routing: Towards More Efficient and Scalable Mixture of Experts Models | Zhou, D., et al. | 2022 | Giới thiệu MoEAR, một biến thể của MoE sử dụng router thích nghi để điều chỉnh số lượng experts được kích hoạt. |
Lưu ý: Bảng này chỉ liệt kê một số nghiên cứu nổi bật về MoE. Có rất nhiều nghiên cứu khác về MoE được công bố trong những năm gần đây, bạn có thể tìm kiếm thêm thông tin trên các trang web khoa học như Google Scholar hoặc arXiv.
Nhận xét
Mixture of Experts (MoE) là một kỹ thuật đầy hứa hẹn, mang đến nhiều lợi ích so với các mô hình truyền thống. MoE cho phép chúng ta xây dựng các mô hình máy học hiệu quả hơn, có khả năng xử lý dữ liệu phức tạp, đồng thời tiết kiệm tài nguyên và thời gian huấn luyện. Mặc dù còn một số hạn chế như khả năng tổng quát hóa và sự phức tạp trong triển khai, MoE vẫn là một hướng nghiên cứu hấp dẫn trong lĩnh vực máy học. Với sự phát triển của các công nghệ như Transformer và các kỹ thuật gating mới, MoE hứa hẹn sẽ ngày càng được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau, từ xử lý ngôn ngữ tự nhiên đến khoa học y tế.
Kết luận
MoE là một kỹ thuật đầy tiềm năng, cho phép chúng ta xây dựng các mô hình máy học hiệu quả hơn mà không cần phải tăng kích thước của mô hình một cách quá mức. MoE sử dụng sparsity và conditional computation để tối ưu hóa quá trình huấn luyện và thực thi. Với sự phát triển của các công nghệ như Transformer và các kỹ thuật gating mới, MoE hứa hẹn sẽ đóng vai trò quan trọng trong tương lai của lĩnh vực máy học.
Lưu ý: Bài viết này đã giới thiệu cơ bản về MoE. Để hiểu rõ hơn về các khía cạnh kỹ thuật và các ứng dụng cụ thể, bạn cần tham khảo thêm các tài liệu chuyên sâu về chủ đề này.
[++++]
- Đọc thêm kiến thức về AI, Machine Learning
- Nếu bạn cần Dịch vụ marketing AI, liên hệ Click Digital ngay.
- Hoặc đầu tư vào trí tuệ nhân tạo bằng cách mua token Saigon (ký hiệu: SGN) thông qua sàn giao dịch Pancakeswap: https://t.co/KJbk71cFe8 (đừng lo lắng về low liquidity, hãy trở thành nhà đầu tư sớm) (cách mua: tìm hiểu trên Google về thao tác giao dịch trên sàn phi tập trung Pancakeswap, cực kỳ an toàn).
- Được hỗ trợ bởi Công ty Click Digital
- Nâng cao kiến thức về AI + Machine Learning
- Địa chỉ token trên mạng BSC: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
- Invest in Artificial Intelligence by BUYING Saigon token (symbol: SGN) through the Pancakeswap exchange: https://t.co/KJbk71cFe8 (do not worry about low liquidity, be an early investor) (how to buy: search on Google for instructions on trading on the decentralized Pancakeswap exchange, it’s secure).
- Backed by Click Digital Company
- Enhancing AI + Machine Learning knowledge
- BSC address: 0xa29c5da6673fd66e96065f44da94e351a3e2af65
- Twitter: https://twitter.com/SaigonSGN135/
- Staking SGN: http://135web.net/
Digital Marketing Specialist