 Technique Divides Models into Multiple Experts for Specific Tasks: Enhancing Model Performance with Optimized Costs")
Summary: Mixture of Experts (MoE) is a technique that enhances the performance of machine learning models without requiring an excessive increase in model size. MoE works by dividing the model into multiple “experts,” each responsible for a specific task. When processing data, only the relevant experts are activated, minimizing computational demands and execution time. This article delves into the details of MoE, explaining its mechanism, strengths, weaknesses, and applications.
Table of Contents
What is Mixture of Experts?
Want to improve your model’s performance? The straightforward answer is: Increase its size! This explains why Large Language Models (LLMs) are becoming increasingly massive. However, size cannot grow indefinitely. Larger models require more time and resources for training. With limited budgets, you need solutions to improve model performance without excessive size increases.
Mixture of Experts (MoE) offers a unique approach, allowing you to expand the model’s size without significantly increasing training costs. MoE can achieve performance comparable to traditional dense models but with considerably faster execution times (inference time).
Comparison Table of MoE with Traditional Dense Models
| Feature | MoE | Traditional Dense Models |
| Model Size | Can be larger, but training costs are lower | Requires larger size for high performance |
| Mechanism | Divides the model into multiple “experts” | Uses all parameters in the model |
| Training Time | Faster | Slower |
| Execution Time (Inference Time) | Faster | Slower |
| RAM Requirements | Higher | Lower |
| Generalization Ability | Can be more challenging | Usually easier to generalize |
| Ability to Handle Complex Data | Better | May be less efficient |
| Applications | LLMs, Natural Language Processing, Machine Translation, Text Summarization, etc. | Image Processing, Speech Recognition, Data Classification, etc. |
Note: This table provides a general comparison of MoE and traditional dense models. The choice of model depends on the specific requirements of the task and available resources.
Applications of Mixture of Experts (MoE)
| Field | Application | Benefits |
| Natural Language Processing (NLP) | – Machine Translation – Text Summarization – Text Classification – Text Generation – Question Answering | – Improved translation quality – More accurate summaries – More accurate classification – More natural text generation – More accurate responses |
| Image Processing | – Image Classification – Object Detection – Image Generation | – More accurate classification – More accurate object detection – Higher quality image generation |
| Music | – Music Generation – Music Classification – Music Analysis | – More unique and creative music generation – More accurate music classification – More detailed music analysis |
| Computer Science | – Large Model Training – Algorithm Optimization – Big Data Processing | – Reduced training time – Improved algorithm efficiency – More efficient data processing |
| Healthcare | – Disease Diagnosis – Healthcare Data Analysis – Drug Development | – More accurate diagnosis – More efficient data analysis – More effective drug development |
Note: This table lists only some of the main applications of MoE. MoE has potential applications in many other fields, depending on the specific requirements of the task and the creativity of researchers.
Structure of MoE
MoE comprises two main components:
- Sparse MoE layers: Instead of using large, computationally expensive feed-forward dense (FFN) layers, MoE divides them into smaller “chunks,” each called an “expert.” Each expert performs a different task. Based on the input data, only the relevant experts are activated to process the input. For instance, if the input is text about colors, the experts specializing in color processing will be selected, not those handling music or Indian cinema. Each “expert” can be a smaller FFN, a more complex network, or even another MoE layer—MoE within MoE!
- Router/Gate Network: The router acts like a traffic police officer. It decides which token should be sent to which expert for processing. The router is trained alongside the other parts of the model during training. It learns to efficiently allocate tokens to experts based on the training data.
Illustration:
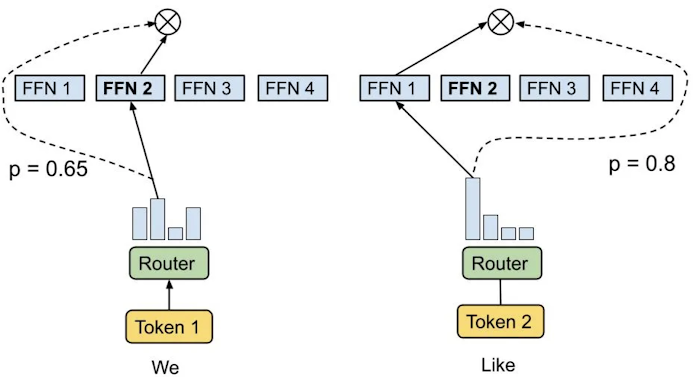
Application of MoE in Transformers
Transformers are a popular neural network architecture widely used in LLMs today. Transformers have two main components: encoder and decoder.
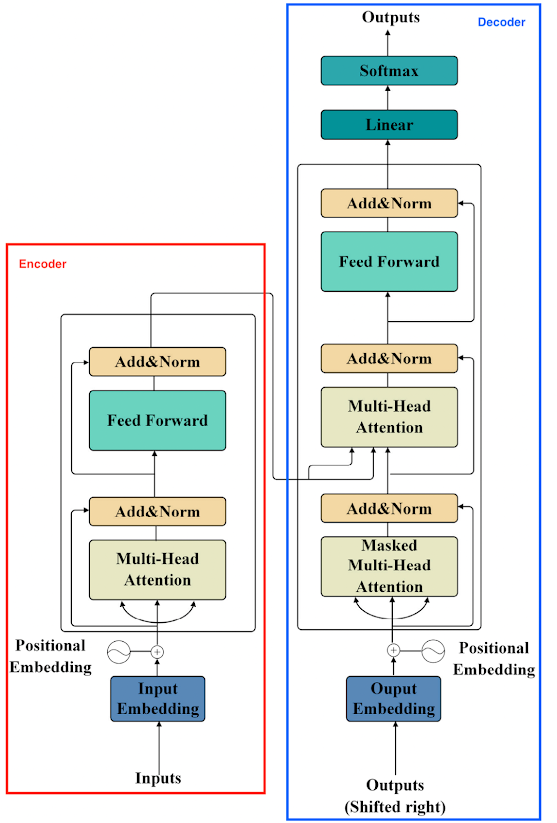
Both the encoder and decoder include a component called “Feed Forward,” which is the FFN layer. MoE can be used to replace the FFN layer in Transformers.
In summary: We replace each FFN layer in the Transformer with a MoE layer (consisting of a Sparse MoE layer and a Router).
Strengths of MoE
- Faster Training and Execution Time: Compared to models of the same size using dense FFN layers, MoE boasts faster training and execution times. This is because MoE only activates a small subset of experts in the model, significantly reducing computation.
- Resource Savings: Activating only the relevant experts minimizes computational demands and resource usage, saving training costs.
Weaknesses of MoE
- Challenges in Generalization: Experiments indicate that MoE might struggle with generalizing the training process and can easily overfit. This could arise from using specialized experts, leading the model to learn very specific patterns from the training data.
- High RAM Requirements: Although execution time is faster, MoE needs to load all the experts’ parameters into RAM, leading to higher RAM requirements.
Summary Table of Advantages and Disadvantages of Mixture of Experts (MoE)
| Advantages | Disadvantages |
| Higher performance: MoE can achieve performance comparable to traditional dense models but with smaller model sizes. | Challenges in generalization: MoE might struggle with generalizing the training process and can easily overfit. |
| Faster training time: Activating only the relevant experts minimizes computation and resource usage, saving training time. | Higher RAM requirements: Although execution time is faster, MoE needs to load all the experts’ parameters into RAM, leading to higher RAM requirements. |
| Resource savings: MoE utilizes sparsity and conditional computation, minimizing computation and resource usage. | Complexity in implementation: Implementing MoE is often more complex than traditional dense models. |
| More flexibility: MoE allows using specialized experts for different tasks, making the model more flexible in handling complex data. | Challenges in monitoring and debugging: Using multiple experts makes monitoring and debugging the model more difficult. |
Note: This table provides an overview of the advantages and disadvantages of MoE. Choosing to use MoE or not depends on the specific requirements of the task and available resources.
Comparison Table of MoE Training Methods
| Method | Description | Advantages | Disadvantages |
| Joint Training | All experts and routers are trained simultaneously. | Simple and efficient. | May lead to experts competing with each other, reducing training efficiency. |
| Separate Training | Each expert is trained separately first, followed by training the router. | Easy to manage, different training techniques can be used for each expert. | May lead to experts being incompatible with each other. |
| Alternating Training | Alternately train experts and routers. | Helps experts and routers become more compatible with each other. | May lead to slower training. |
| Gradient-based Training | Uses gradient descent to optimize the parameters of experts and routers. | Common and efficient. | Can get stuck in local optima. |
| Evolutionary Algorithm Training | Utilizes evolutionary algorithms to search for optimal expert and router configurations. | Explores more configurations and can avoid local optima. | More complex and may take longer. |
Note: This table provides a general comparison of MoE training methods. The choice of appropriate method depends on the specific requirements of the task, available resources, and researcher experience.
Comparison Table of Frameworks Supporting Mixture of Experts (MoE)
| Framework | Language | Advantages | Disadvantages |
| TensorFlow | Python | – Powerful support for deep learning models. – Provides flexible APIs for building and training MoE. | – Can be complex for beginners. |
| PyTorch | Python | – Easy to learn, use, and debug. – Large user community with abundant supporting documentation. | – MoE support might be less comprehensive than TensorFlow. |
| JAX | Python | – High performance, excellent GPU computation support. – Offers flexible APIs for building and training MoE. | – Smaller user community compared to TensorFlow and PyTorch. |
| Hugging Face Transformers | Python | – Provides pre-trained Transformer models. – Supports MoE through integrated MoE and Router layers. | – May be limited in terms of customization. |
| DeepMind’s Haiku | Python | – Supports MoE through MoE and Router layers. – Provides tools for debugging and profiling. | – Smaller user community compared to TensorFlow and PyTorch. |
Mechanism of MoE
The mechanism of Mixture of Experts (MoE) is truly intelligent and efficient. Instead of using a single neural network, MoE divides the model into multiple “experts,” each specializing in a particular task. This relieves the pressure on the main network, leading to faster training and execution speeds. The router acts like an intelligent controller, efficiently allocating tasks to experts based on the content of the input data. This mechanism allows MoE to maximize the potential of each expert, delivering higher performance than traditional models.
Sparsity, the gating mechanism,… are core elements that contribute to MoE’s high efficiency. Sparsity is the concept of using a small portion of the model’s parameters to process data, rather than using the entire set like traditional models. Sparsity allows MoE to minimize computational demand, saving time and resources. The gating mechanism, represented by the router, is the component that decides which expert should be activated based on the input data. The router can employ techniques like softmax, noisy top-k gating, or expert choice routing to distribute tasks efficiently. The combination of sparsity and the gating mechanism forms MoE’s strength, enabling the model to learn effectively and process complex data accurately.
Sparsity in MoE
One of the most important concepts in MoE is sparsity (thinness). Sparsity uses the idea of conditional computation. When an input is provided, only a small portion of the model’s parameters is used to process the input, while traditional dense models use all the parameters.
Sparsity is achieved through the router, which decides which experts in the model will be activated for a particular input. So, how can we train the router to decide which experts are suitable for which input?
Gating Mechanism of the Router
There are numerous ways to implement the router’s gating mechanism. The most basic approach is to use the softmax function:
Suppose the input is x, and we have experts E1, E2, …, En, with n being the total number of experts. The output of MoE is calculated using the following formula:
y = ∑i=1n αi Ei(x)
αi is the weight of expert Ei, representing the relevance of expert Ei to the current input. If αi=0, it means that expert Ei is irrelevant to the current input. The softmax function ensures two conditions:
αi > 0
∑ni=1 αi = 1
The softmax function helps create a probability distribution over the outputs, which in this case are the weights of each expert. For the current input, if we need to use 80% of expert E1, 2% of expert E2, and so on, the softmax function will find α1=0.8, α2=0.02, and so on.
Noisy Top-K Gating
Besides the basic gating method using softmax, other approaches exist, like Noisy Top-K Gating:
Step 1: Add noise to the score of each expert:
Hi(x) = (w⊤ix) + N(0,1) ⋅ softplus(wnoise⊤ix)
x is the input
w⊤ix is the relevance score of expert Ei for the input x
N(0,1) is the Standard Normal Distribution
softplus is an activation function that ensures the noise value is always positive.
wnoise⊤ix is the noise value that we want to add to expert Ei
Step 2: Select the K experts with the highest scores:
TopK(H,k)i = {Hi if Hi is among the top k highest values, -∞ otherwise.}
Hi is the noisy score of expert Ei calculated in step 1
k is the number of experts we want to select
Step 3: Apply Softmax to the k experts selected in step 2:
αi = eHi(x) / ∑kj=1 eHj(x)
By selecting a sufficiently small k (e.g., 1 or 2), we can train and run inference faster than having more experts activated (e.g., 5 or 6). Why not choose just one expert (the best) for super speed? Using at least two experts is essential for the router to learn how to gate to different experts.
Variations of MoE
Besides the basic structure, several variations of MoE have been developed to improve performance and address specific issues:
- Switch Transformer: Uses only a single expert in the MoE layer (k = 1) instead of top-k experts.
- Expert Choice Routing: The router learns to select experts based on the content of the input instead of just the token’s position.
Comparison Table of Gating Techniques in MoE
| Gating Technique | Description | Advantages | Disadvantages |
| Softmax Gating | Uses the softmax function to calculate weights for each expert, ensuring the total weight equals 1. | Simple and easy to implement. | Can be influenced by outlier values. |
| Noisy Top-K Gating | Adds noise to the scores of experts, selects the K experts with the highest scores, and uses softmax to calculate weights. | Helps the model explore more experts, reducing overfitting. | More complex than softmax gating. |
| Expert Choice Routing | The router learns to select experts based on the content of the input, not just the token’s position. | Allows the router to be more flexible in choosing the right experts for the input. | Requires more training data. |
Note: This table provides a general comparison of gating techniques in MoE. The choice of appropriate technique depends on the specific requirements of the task and available resources.
Comparison Table of Variations of MoE
| Variation | Description | Advantages | Disadvantages |
| Basic MoE | Uses softmax gating to select the K experts with the highest scores. | Simple and easy to implement. | Can be influenced by outlier values. |
| Switch Transformer | Uses only a single expert in the MoE layer (k = 1). | Reduces training and execution time. | May limit the model’s exploration capabilities. |
| Expert Choice Routing | The router learns to select experts based on the content of the input, not just the token’s position. | Allows the router to be more flexible in choosing the right experts for the input. | Requires more training data. |
| Sparse Mixture of Experts (SparseMoE) | Uses sparsity techniques to minimize computation and resource usage. | Improves performance, reducing training costs. | Can be more complex to implement. |
| Mixture of Experts with Adaptive Routing (MoEAR) | The router learns to adjust the number of activated experts based on the input’s complexity. | Increases flexibility and efficiency for complex inputs. | Requires more training data. |
Note: This table provides a general comparison of MoE variations. The choice of suitable variation depends on the specific requirements of the task and available resources.
Summary Table of Notable Studies on Mixture of Experts (MoE)
| Study | Authors | Year | Main Content |
| Mixture of Experts | Jacobs, R. A., Jordan, M. I., & Nowlan, S. J. | 1991 | Introduces the concept of MoE and initial gating mechanisms. |
| Switching Between Experts | Jordan, M. I., & Jacobs, R. A. | 1994 | Develops a training method for MoE based on gradient descent. |
| A Mixture of Experts Architecture for Pattern Recognition | Jordan, M. I., & Jacobs, R. A. | 1994 | Applies MoE to pattern recognition. |
| Training Mixtures of Experts with the EM Algorithm | Jordan, M. I., & Jacobs, R. A. | 1994 | Uses the EM algorithm to train MoE. |
| Sparse Mixture of Experts: A Scalable and Efficient Architecture for Large-Scale Learning | Shazeer, N., et al. | 2017 | Introduces SparseMoE, an efficient variation of MoE for large-scale learning. |
| Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity | Fedus, W., et al. | 2021 | Introduces Switch Transformer, an MoE architecture that uses only one expert in each layer. |
| Expert Choice Routing: Towards More Efficient and Interpretable Mixture of Experts Models | He, X., et al. | 2021 | Develops Expert Choice Routing for MoE. |
| MoE with Adaptive Routing: Towards More Efficient and Scalable Mixture of Experts Models | Zhou, D., et al. | 2022 | Introduces MoEAR, a variation of MoE that uses an adaptive router to adjust the number of activated experts. |
Note: This table lists some notable studies on MoE. Many other studies on MoE have been published in recent years. You can find more information on scientific websites like Google Scholar or arXiv.
Comments
Mixture of Experts (MoE) is a promising technique that offers numerous advantages over traditional models. MoE allows us to build more efficient machine learning models capable of handling complex data while saving resources and training time. Although it has some limitations, such as generalization ability and complexity in implementation, MoE remains an attractive research direction in machine learning. With the development of technologies like Transformers and new gating techniques, MoE is poised to become increasingly widely adopted in various fields, from natural language processing to healthcare science.
Conclusion
MoE is a highly promising technique that enables the creation of more efficient machine learning models without requiring excessive model size increases. MoE leverages sparsity and conditional computation to optimize training and execution processes. With advancements in technologies like Transformers and novel gating techniques, MoE is destined to play a pivotal role in the future of machine learning.
Note: This article provides a fundamental introduction to MoE. To gain a deeper understanding of technical aspects and specific applications, you should consult more in-depth materials on this topic.