
Have you ever tried to eat a giant pizza and realized you need to slice it into smaller pieces to make it easier? Chunking in Machine Learning works in a similar way! Instead of forcing the computer to “chew” on a massive chunk of data at once, we break it down into smaller, more digestible portions.
Table of Contents
What is Chunking?
Chunking simply means dividing data into smaller “chunks” of manageable size. Instead of processing all the data at once, Large Language Models (LLMs) only process smaller chunks, making them less stressed and more computationally efficient.

Chunking Examples:
Imagine you have a 100-page document. If you give the whole document to an LLM to process, it would be overwhelmed and unable to handle it effectively. Dividing the document into sentences or paragraphs would make it easier for the LLM to understand the information.
Similarly, when you have a 4K high-resolution image, you can’t give the whole image to AI for processing at once. Chunking helps to divide the image into smaller pieces so that AI can analyze each part efficiently.
Comparing Chunking Techniques in RAG:
| Technique | Approach | Advantages | Disadvantages |
| Traditional Chunking | Dividing documents into fixed-size chunks (e.g., 512 tokens) | Easy to implement | Loss of context |
| Sliding Window | Dividing documents with overlapping sliding windows | Preserves some context | Can create many overlapping chunks |
| Multiple Context Window Lengths | Dividing documents with different window lengths | Preserves better context | Requires more resources |
| Multi-pass Document Scans | Scanning documents multiple times with different window lengths | Preserves the best context | Very time-consuming and resource-intensive |
| Late Chunking | Processing the entire text before creating embeddings | Preserves the best context, more efficient | More complex, requires more resources |
What is Late Chunking?
Late Chunking is an advanced chunking technique. Instead of dividing the document into chunks before creating embeddings, Late Chunking processes the entire text first before creating embeddings for each chunk. This ensures that the embeddings for each chunk are rich in context from the entire document, preserving the important connections between different parts of the information.
Comparing Traditional Chunking and Late Chunking:
| Approach | Approach | Advantages | Disadvantages |
| Traditional Chunking | Dividing documents before creating embeddings | Easy to implement | Loss of context |
| Late Chunking | Processing the entire text before creating embeddings | Preserves context | More complex |
Chunking Fundamentals in RAG
In Retrieval-Augmented Generation (RAG), chunking is the process of dividing a long document into smaller “chunks” (each chunk containing around 512 tokens). This is crucial because LLMs are often limited in the amount of text they can process at once. By dividing the document into smaller chunks, each part can be stored individually in a Vector Database.
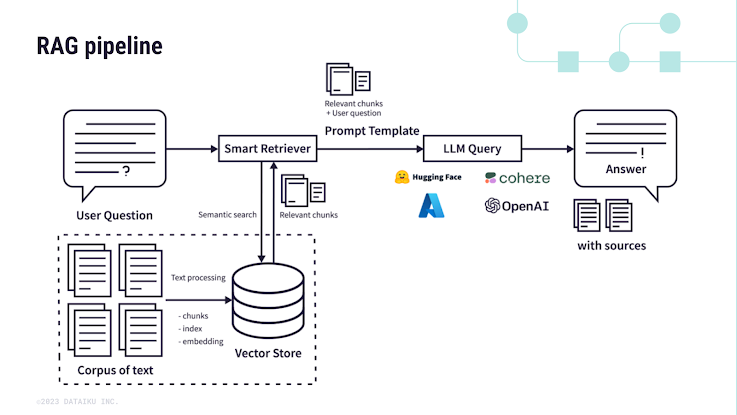
Steps in a Basic RAG System:
- Dividing the Document: The document is divided into smaller chunks (e.g., 512 tokens per chunk).
- Creating Embeddings: Each chunk is encoded into a vector representation.
- Storing Embeddings: These vectors are stored in a Vector Database.
- Retrieving Information: When a user asks a question, the Embedding Model encodes the question into a vector.
- Searching for Relevant Chunks: This vector is then used to search and retrieve the most relevant text chunks from the Vector Database.
- Synthesizing an Answer: The retrieved chunks are then fed into an LLM to synthesize an answer based on the information contained in those chunks.
Limitations of Basic Chunking Techniques
Traditional chunking methods often lead to the loss of important connections between different parts of the text. For example, when you cut a document into smaller sections, those sections become isolated and lose their relationship to other sections. The embedding vectors of these isolated segments can only capture internal information within the segment, but not related information between different segments.
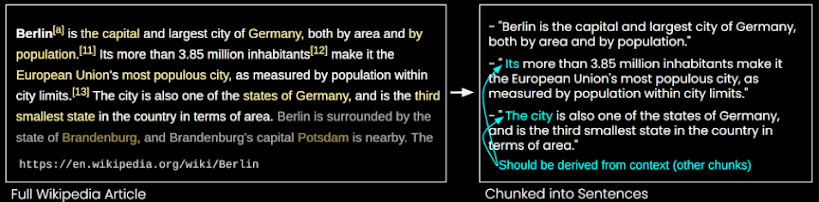
Ngữ nghĩa bị cắt mất khi ta dùng kỹ thuật chunking cơ bản.
Example:
Consider this paragraph:
“Berlin is the capital and largest city of Germany, both in terms of area and population. Its more than 3.85 million inhabitants make it the most populous city in the European Union, measured by population within city limits. The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.”
If we split this paragraph into individual sentences, words like “it” and “the city” will lose their contextual connection to “Berlin,” making it difficult for the LLM to understand the true meaning of the sentences.
Late Chunking as a Solution
Late Chunking addresses the problem of losing context by applying the transformer layer of the embedding model to the entire text before dividing it into chunks. This approach ensures that each created chunk includes contextual information from the entire text, helping the LLM understand the meaning of each segment more accurately.
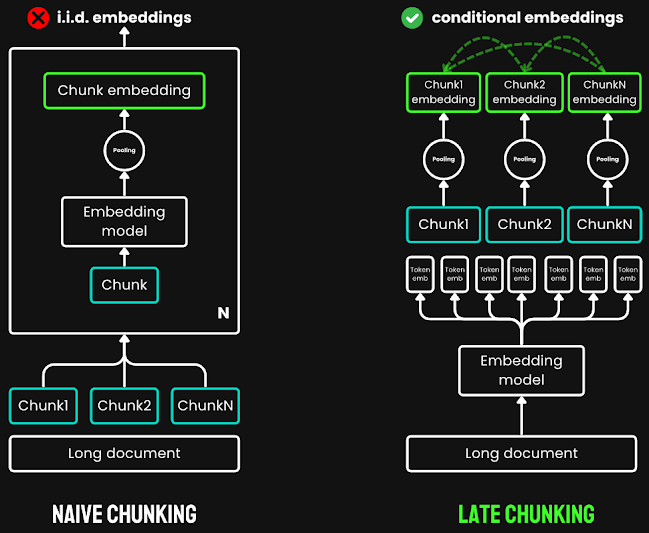
Example:
When applying Late Chunking to the paragraph about Berlin above, the vectors representing “the city” now contain information about the previously mentioned “Berlin,” helping the LLM easily identify the connection between the sentences.

How Late Chunking Works
- Processing the entire text: Applying the transformer layer of the embedding model to the entire text.
- Creating token embeddings: Generating a sequence of vector representations for each token.
- Dividing into chunks: Dividing this sequence of token vectors into chunks based on boundary cues (e.g., sentences, paragraphs).
- Creating chunk embeddings: Applying mean pooling on the token vectors within each chunk to create an embedding vector for that chunk.
Late Chunking retains the context of the entire text in each chunk, enabling the LLM to understand the connections between different parts of the information.
Advantages of Late Chunking
- Preserves context: Late Chunking helps preserve the contextual information of the entire document within each chunk.
- More efficient: Late Chunking is more effective in retrieving information compared to traditional chunking methods.
- Easy to implement: Late Chunking can be easily implemented by modifying a few lines of code in the embedding model.
Disadvantages of Late Chunking
While promising, Late Chunking also has some drawbacks:
- Complexity: Late Chunking is more complex than traditional chunking, requiring the processing of the entire text before creating embeddings. This can lead to longer processing times, especially for long documents.
- Resource requirements: Late Chunking requires the use of long-context embedding models, which often require more computational resources than traditional embedding models.
- Technical adjustments: Depending on the type of document and intended use, it may be necessary to adjust the chunking technique and select appropriate boundary cues to achieve optimal efficiency.
- Uneven effectiveness: Late Chunking’s effectiveness may vary for different document types. For example, it may be more effective for documents with a clear structure but less effective for documents with complex structures or fewer contextual connections.
- Limited testing: Late Chunking is a relatively new technique, so there is still limited testing and research on its real-world effectiveness.
Despite these drawbacks, Late Chunking is still considered a promising technique for improving RAG’s information processing capabilities. With technological advancements and further research on Late Chunking, hopefully these limitations will be overcome in the future.
Comparing Late Chunking with Naive Chunking and ColBERT
| Technique | Approach | Advantages | Disadvantages |
| Naive Chunking | Dividing documents before creating embeddings | Easy to implement, less resource-intensive | Loss of context |
| Late Chunking | Processing the entire text before creating embeddings | Preserves context, more efficient | More complex, requires more resources |
| ColBERT | Not dividing documents, directly comparing tokens | Highly efficient, preserves good context | Requires a lot of resources, difficult to implement |
Concluding Remarks
Late Chunking is a promising technique for improving RAG’s information processing capabilities. It effectively addresses one of the biggest challenges of traditional chunking—the loss of context. While Late Chunking is still under development and research, it has proven effective in many experiments, opening up significant potential for the future of RAG.
Note
- Long-context embedding models: Late Chunking requires the use of long-context embedding models, capable of processing a large number of tokens (e.g., 8192 tokens).
- Boundary cues: Boundary cues (e.g., sentences, paragraphs) are used to divide the token vectors into chunks.
References
- JinaAI: Late Chunking: https://jina.ai/blog/late-chunking-long-context-embedding-models/
- GitHub Repo: https://github.com/jina-ai/late-chunking
- Colab Notebook: https://colab.research.google.com/drive/15vNZb6AsU7byjYoaEtXuNu567JWNzXOz